
Learning from Stored Workflows: Retrieval for Better Orchestration
Introduction
As enterprises adopt tool-using AI agents to automate complex workflows, a persistent challenge arises: how can we enable these agents to draw on prior successes when appropriate, instead of approaching each new task as a blank slate? Without such a mechanism, an agent is likely to plan a task from first principles every time, even if it has completed similar tasks in the past.
This results in two key inefficiencies. First, it means the agent must repeatedly come up with the same sequences of steps, rediscovering familiar tool calls and formatting logic. Second, it introduces inconsistency: small input variations can lead to different planning paths, output styles, and divergent final results.
Humans naturally avoid such inefficiencies by recalling and adapting past solutions. We explored how to give AI agents a similar advantage, by allowing them to store and retrieve representations of successful workflows.
The Workflow Memory System
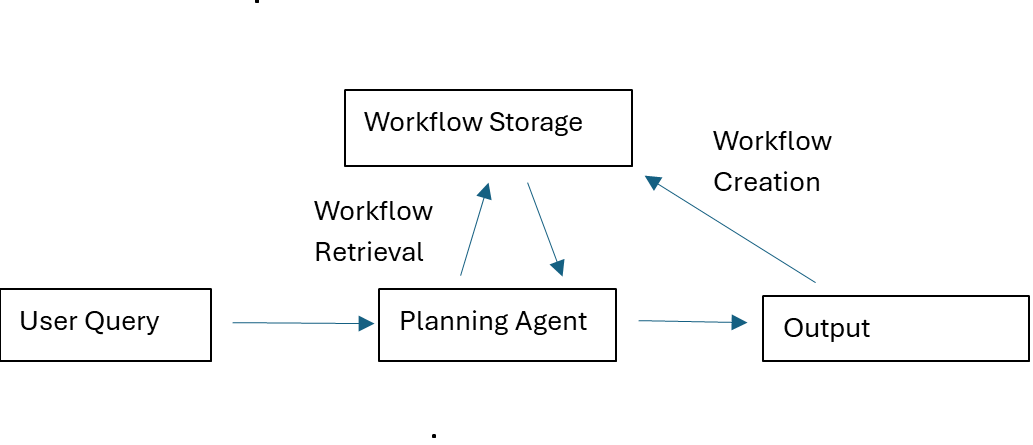
We implemented a minimal yet general architecture for workflow memory. The system follows a familiar pattern in memory system, with three core processes: creation, storage, and retrieval.
1. Workflow Creation
After completing a nontrivial, multi-step task, our planning agent triggers a special SaveWorkflow tool. This tool generates a natural-language summary outlining the sequence of function calls and input parameters used. The user can review and edit this summary for clarity or precision. The finalized workflow is stored in structured JSON format, paired with a readable natural-language description.
2. Workflow Storage
The created workflow is then embedded into a vector space using the text of the original user query that produced it. This embedding serves as a key, allowing similar queries to retrieve relevant workflows. The result is a memory bank that captures the agent’s procedural knowledge, indexed by user intent.
3. Workflow Retrieval
When the agent receives a new complex query, it invokes another specialized tool, RetrieveRelevantWorkflows. The new query is embedded and compared against stored workflows – we use cosine similarity as a metric. The top-k most similar workflows are returned as context for planning.
In effect, before generating a new plan, the agent can review “how I’ve solved similar tasks before,” leading to more efficient, consistent, and human-like orchestration.
Methodology and Experimental Design
Our proof-of-concept study tested whether this workflow memory mechanism improves plan quality across diverse categories of enterprise tasks.
Dataset
We designed seven base workflows, each representing a specific type of digital or enterprise task:
- Restaurant discovery and sharing
- AI news aggregation
- Hotel search and Confluence documentation
- Company project summarization
- Executive bio compilation
- Topical news summarization
- AI event and hotel planning
For each base workflow, we created five semantically varied prompts to test generalization.
For example, the Restaurant Discovery workflow included variants such as:
- “Find the top 10 restaurants in New York City.”
- “Give me 5 inexpensive vegan restaurants in Manhattan.”
- “What are 3 Vietnamese restaurants in Los Angeles?”
This produced a total of 35 unique task prompts (7 workflows × 5 prompts each).
Experimental Treatments
Each prompt was evaluated under two conditions:
- Baseline (No retrieval): The agent plans each task from scratch.
- Workflow Retrieval: The agent retrieves and reads similar stored workflows before planning.
To measure variability, we conducted 14 independent runs per query for both treatments, resulting in 980 total trials (7 workflows × 5 prompts × 2 treatments × 14 runs).
Testing Setup
In our experiment, the agent acted purely as a planning agent: it knew the available tools and their capabilities but did not have the privileges to execute them. Its task was to generate a step-by-step plan describing how it would complete each query, without performing any actions. This approach isolates planning quality from runtime variability, allowing evaluation to focus solely on the generated plans rather than the outcomes of tool execution.
Evaluation Framework
We assessed the generated plans using several different quantitative metrics. First, we employed two different measures of the similarity between the generated plan and human-vetted “gold-standard” plan:
- LLM Critique of Similarity to Gold Standard: an LLM evaluator scored how closely the generated plan matched the gold-standard plan, on a 10-point scale.
- Cosine Similarity to Gold Standard: Each generated plan was embedded and compared to the “gold standard” plan, again using cosine similarity as a metric.
While these measures don’t capture every aspect of plan similarity, together they provide a meaningful estimate of the generated plan’s closeness to the gold standard.
We also sought to estimate the overall quality of the plan, independently of similarity to the gold standard. We used a separate LLM critique to measure this:
- LLM Critique of Quality: How well the plan is expected to accomplish the initial query, on a 10-point scale.
Finally, we cared about the consistency of the generated plans across repeated runs for a single query. To estimate this this, we used another embedding-based metric:
- Cosine Similarity-based Consistency: defined as the average pairwise cosine similarity between generated plans for the same query. Higher average pairwise cosine similarity corresponds to lower variance in generated plans.
Analysis
Results:
The following table shows average differences between outcomes in the Workflows Retrieval condition vs the Baseline (no workflows) condition, for these 4 metrics. Differences are given in units of standard deviation. Positive values indicate improved performance in the Workflows Retrieval condition over the baseline.
The quality metrics—LLM Critique of Quality, LLM Critique of Similarity to Gold Standard, and Cosine Similarity to Gold Standard, consistently show that loading workflows leads to measurable improvements in plan quality.
However, in two of our prompt categories, loading workflows also resulted in decreases in plan consistency. This phenomenon warrants further investigation.
We also conducted a regression analysis to test whether the closeness of the retrieved workflows to the query (measured as the cosine similarity) predicted the gains on the metrics shown above. Intuitively, the answer should be yes: the better the “match” is between the retrieved workflows and the query, the more help those retrieved workflows should provide.
Confirming this intuition, the analysis revealed a positive, statistically significant correlation, indicating that higher similarity between the query and the retrieved workflows corresponded to greater improvements in both plan quality and consistency.
Conversely, if the top retrieved workflows were not great matches for the query, they could mislead the planning agent and have negative effects on the quality and consistency of the generated plans. We also observed that when similarity fell below a certain threshold, the agent sometimes behaved erratically, taking the wrong lessons from the retrieved queries and repeating incorrect steps in the generated plans. We think this behavior likely explains the decreases in consistency for some prompt categories noted above, highlighting a trade-off between imitating past successes and adapting to novel tasks.
Key Findings and Insights
Here are our key takeaways from this work:
- Stored Workflows Improve Plan Quality: Across 980 runs, providing workflow context consistently improved plan quality, as measured by both LLM critique scores and embedding similarity to gold-standard workflows. The agent also produced better step ordering and more complete tool invocation sequences.
- Similarity Drives Benefit Magnitude: The closer a new query was to a stored one in embedding space, the greater the improvement. This validates retrieval-based transfer learning at the plan level.
- Overfitting to Past Success: When query similarity to the retrieved workflows was only moderate, the agent sometimes over-relied on retrieved workflows, reproducing irrelevant portions. This might be addressed by imposing a similarity threshold below which stored workflows are not retrieved, allowing the agent to leverage stored workflows more conservatively.
- Representation Format Matters: We experimented informally with two different workflow storage formats: natural-language (NL) summaries and structured JSON workflow representations. We found that JSON workflows enhanced retrieval precision and improved tool grounding, while NL summaries remained valuable for readability and manual review.
Broader Implications and Future Directions
Building on the findings from this study, there are several promising directions to extend and apply workflow memory for AI agents. Below, we outline key areas for further investigation and development:
- Workflow Memory as a Procedural Cache - This workflow store acts as a “procedural cache”: it can be reset, filtered, versioned, and shared across users, enabling enterprise-scale reproducibility.
- A Lightweight Alternative to Finetuning - Because no model weights are updated, the Workflow Memory approach is a model-agnostic and low-cost way to bias tool-calling models toward desired behavioral strategies.
- Cross-Workflow Generalization and Stitching - Future work could cluster individual workflows into higher-level procedural patterns (e.g., “search → summarize → publish”). This would allow the system to generalize across tasks and compose smaller workflows into larger, more complex plans.
- Meta-Controllers: Another direction is to train a meta-controller that, for a given query, determines the optimal balance between relying on retrieved workflows and generating new plans from scratch. This could reduce overfitting to past successes while preserving flexibility for novel tasks.
- A Path to Enterprise-Level Memory Future work could explore multiple agents sharing a common workflow memory, enabling collaborative knowledge accumulation and distributed learning across domains and organizations. As multiple agents accumulate and share workflows, the system could evolve into a form of “institutional memory,” capturing how an entire organization performs recurring operational tasks.
Conclusion
Our experiment demonstrates that Workflow Memory allows AI agents to learn from experience by recalling and reusing their own past successes. Unlike fine-tuning, this approach also supports robust human auditing and modification, and allows for greater traceability and explainability, making it practical for enterprise settings.
By embedding successful workflows and retrieving them as in-context examples, we observed quantifiable improvements in planner outcomes. A scaled-up version of this system would support a qualitative change in AI agent behavior: instead of behaving like a novice at every request, the agent is able to act more like an experienced colleague: it recalls how similar tasks were completed previously and adapts its approach accordingly. Ultimately, this work is one step on the road to enterprise-scale memory for AI: a continuously growing layer of procedural experiences that underpin AI-driven operations.
More From the Journal

Learning from Stored Workflows: Retrieval for Better Orchestration

Learning API Functionality from In-Context Demonstrations for Tool-based Agents
