
Learning API Functionality from In-Context Demonstrations for Tool-based Agents
Agentic Data Intelligence requires accessing a lot of data (structured and unstructured) that are sitting behind APIs. Using APIs is complex as there is an interactive learning process to understand the functionality and parameter schema. As we work toward building agents that can take on more complex, real-world tasks with less manual setup, one of the key capabilities they need is the ability to understand and use new tools on their own. Instead of relying on rigid rules or handcrafted integrations, we want systems that can learn how an API works simply by observing examples — much like how a person picks up a new interface. This post explores how in-context demonstrations make that possible, and how this approach helps our agents become more flexible, capable, and ready to operate in a wide range of environments.
Agents that can reliably use Application Programming Interfaces (APIs) without documentation are crucial for real-world deployment. This situation is a frequent, real-world predicament for tool-based agents that invoke API calls to complete complex enterprise tasks. Most research in tool-based agents assumes that the agent has access to API documentation to understand API functionality and parameter schema. However, in many cases, especially with 3rd party APIs, the documentation can be outdated or non-existent.
Although documentation may be inaccessible, what is available is a corpus of API calls or demonstrations. In this study, we utilize these demonstrations to learn functionality and parameter schema. Prior work has finetuned agents based on API calls [1]. However, in this study, we look at learning from demonstrations in-context, thus requiring no repeated parameter updating. In this post, we go over the highlights of our work, Learning API Functionality from In-Context Demonstrations for Tool-based Agents [2], accepted to the Empirical Methods in Natural Language Processing.
Experimental Setup
Expert Demonstration and Demonstration Format

For our study, we use three datasets to extract “expert demonstrations”, which are API calls generated by “expert” agents that had the original API documentation. A single API call is a demonstration; therefore, an expert trajectory of N steps provides N demonstrations for us to extract. Figure 1 shows an example demonstration we extracted from the WorkBench dataset. For each demonstration, we include the 1) Overall Task/Query, 2) Conversation History/Previous Steps, and 3) Demonstration of the Function. The first two elements provide the context in which the current API call is used.
Expert Demonstration Processing
Now that we have extracted demonstrations, we must decide how to pass them into the agent for in-context learning of functionality. Our three methods + oracle baseline are:
- Directly passing the Expert Demonstrations (DXD)
- Generated Document (GD): Using an LLM-generator to output documentation for the APIs. In this work, a single call to the LLM-generator produces one document for a specific API, given the API’s demonstrations
- Generated Document with Example Calls (GDEC): Using the same demonstrations to produce the generated document from GD, we attach to the generated document the “Demonstration of Function” (from Figure 1) of each demonstration.
- Oracle Baseline - Original Documentation: We are essentially turning the agent into an “expert” agent
Demonstrations from Experience
Self-Exploration on Training Tasks: To supplement the set of demonstrations, we also have the agent perform self-exploration. Given some initial understanding of the API functionality based on expert demonstrations using one of the methods above, we have the agent perform the same training tasks used to extract the expert demonstrations. We then extract experience-based demonstrations from the generated trajectories. The experience-based demonstrations are formatted similarly to expert demonstrations. However, during some API calls, the agent would output its rationale. Therefore, we included those thoughts as well in the experience-based demonstration.
LLM-based Critiques: Given the expense of LLM calls, we would like to extract more feedback from the generated trajectories than the sparse evaluation of task success/failure. Therefore, for each experience-based demonstration, we ask an LLM-based judge to generate a natural language critique of the demonstrations. For each call to the judge, we provide the query, the entire trajectory generated by the agent for the query, the success/failure evaluation, and the specific demonstration to critique. Therefore, if a trajectory has M demonstrations, we call the judge M times, with the input being the same except for the demonstration to focus on. We ask the judge to focus on three criteria: 1) whether or not the call was an unnecessary repeated call, 2) whether or not the parameters were filled in correctly, and 3) whether or not the call was out of order.
Experience-based Demonstration Processing
After we have generated experience-based demonstrations with accompanying LLM-critiques from training tasks, we provide multiple methods to pass them to the agent for test tasks*.
- Directly passing in the experience-based demonstrations (DE)
- Attached Guidelines (AG): We take the experience-based demonstrations with LLM-critiques and have an LLM-based summarizer generate natural language guidelines and warnings for each API. For each API, its generated guidelines text is then attached to the end of the generated documentation (i.e., GD from expert demonstrations) for the given API.
*We include more methods in our paper [2] that revolve around updating and/or regenerating the generated documentation with the experience-based demonstrations
Insights and Observations
Errors in Generated Documents
Hallucinated or Missing Parameters. The LLM-document generator frequently hallucinated input parameters that were not present in the demonstrations, or it would leave out input parameters seen in the demonstrations. The issue persisted even when prompted to only focus on the parameters used in the set of input presentations. To mitigate this problem, we parsed out all parameter names used throughout all the demonstrations of a given API and attached them to the input prompt of the generator to explicitly mention which parameters it must describe. While this setup helps fix the issue for OpenAI models (o3-mini, GPT-4o, GPT-4o-mini) and Gemma, the Mistral model would still only generate documentation that includes a general description of the API with no information on input parameters or return values.
Hallucinated Misinformation. In some cases, the generated document would hallucinate formatting information that would hurt the downstream task completion of the agent. For example, generated documentation for time_min and time_max parameters used in multiple methods of the WorkBench function would sometimes include misinformation about how the parameter values need to include timezone information. Agents that were given these incorrect instructions would get a runtime error when calling functions that used time_min and time_max.
Downstream Results with Multi-step Tasks

Ultimately, the goal of learning API functionality is to enable agents to complete real, multi-step tasks — not just individual function calls. To test this, we evaluated our methods across three benchmarks: WorkBench [3] (office automation), τ-Bench [4] (retail operations), and CRMArena [5] (customer relationship management). Each environment requires agents to reason across multiple API calls — for example, searching for data, retrieving details, and then performing an action such as replying to an email or updating a record.
Main Results.
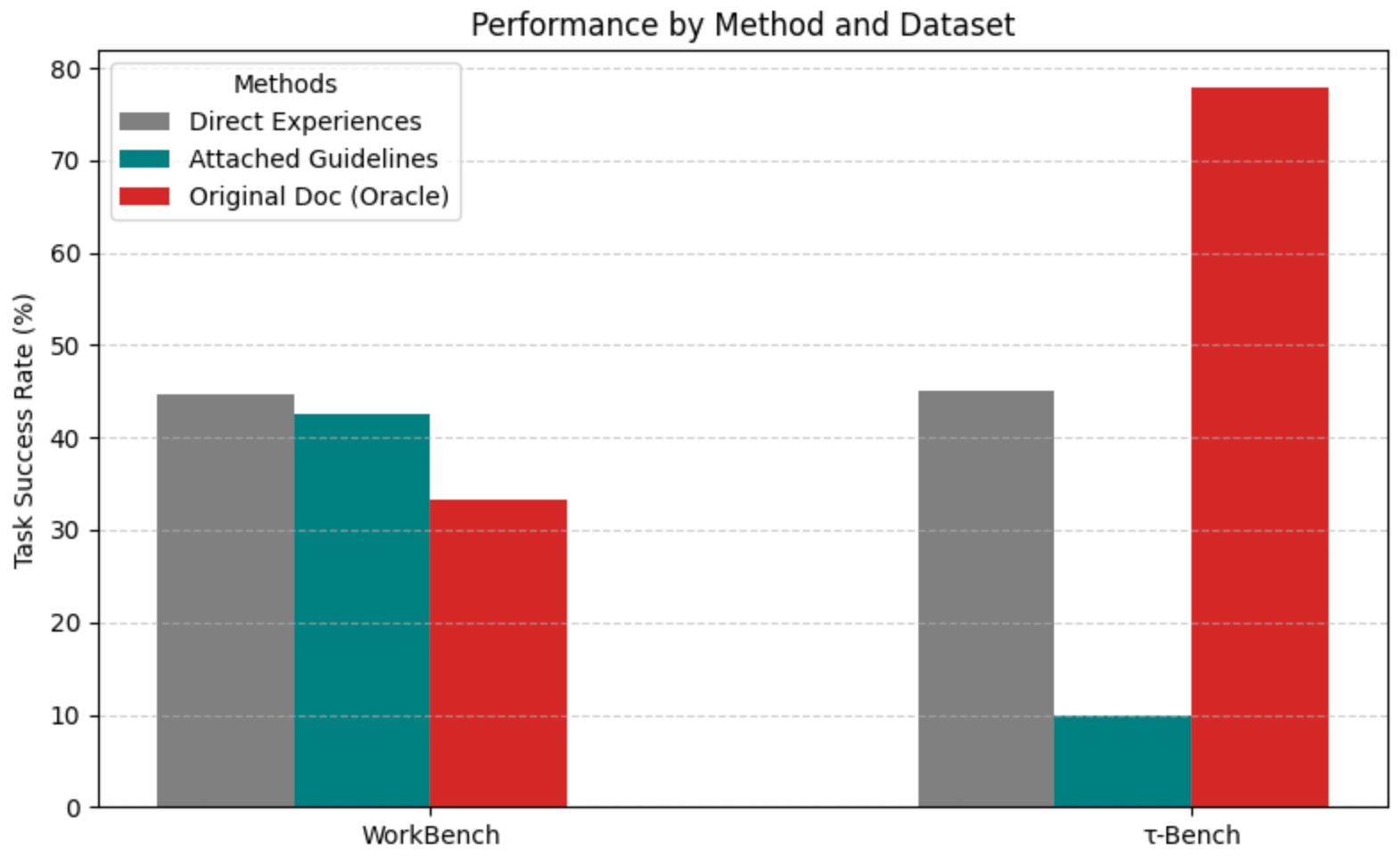
Figure 2 below summarizes how the different learning strategies perform across environments using o1-mini with 5 demonstrations per API. First, Direct Expert Demonstrations (DXD) deliver strong baseline performance, confirming that agents can extract meaningful functional knowledge from seeing examples in-context. However, part of this success can be attributed to data leakage, as the training and test tasks can be very similar (e.g. Train task: “Send email to Nadia”, Test task: “Send email to Dev”). Second, generated documentation (GD) alone provides only modest improvement, but when paired with attached example calls (GDEC), the agent’s ability to complete multi-step tasks rises noticeably. Figure 2 trends show GDEC outperforming GD and approaching the DxD baseline.
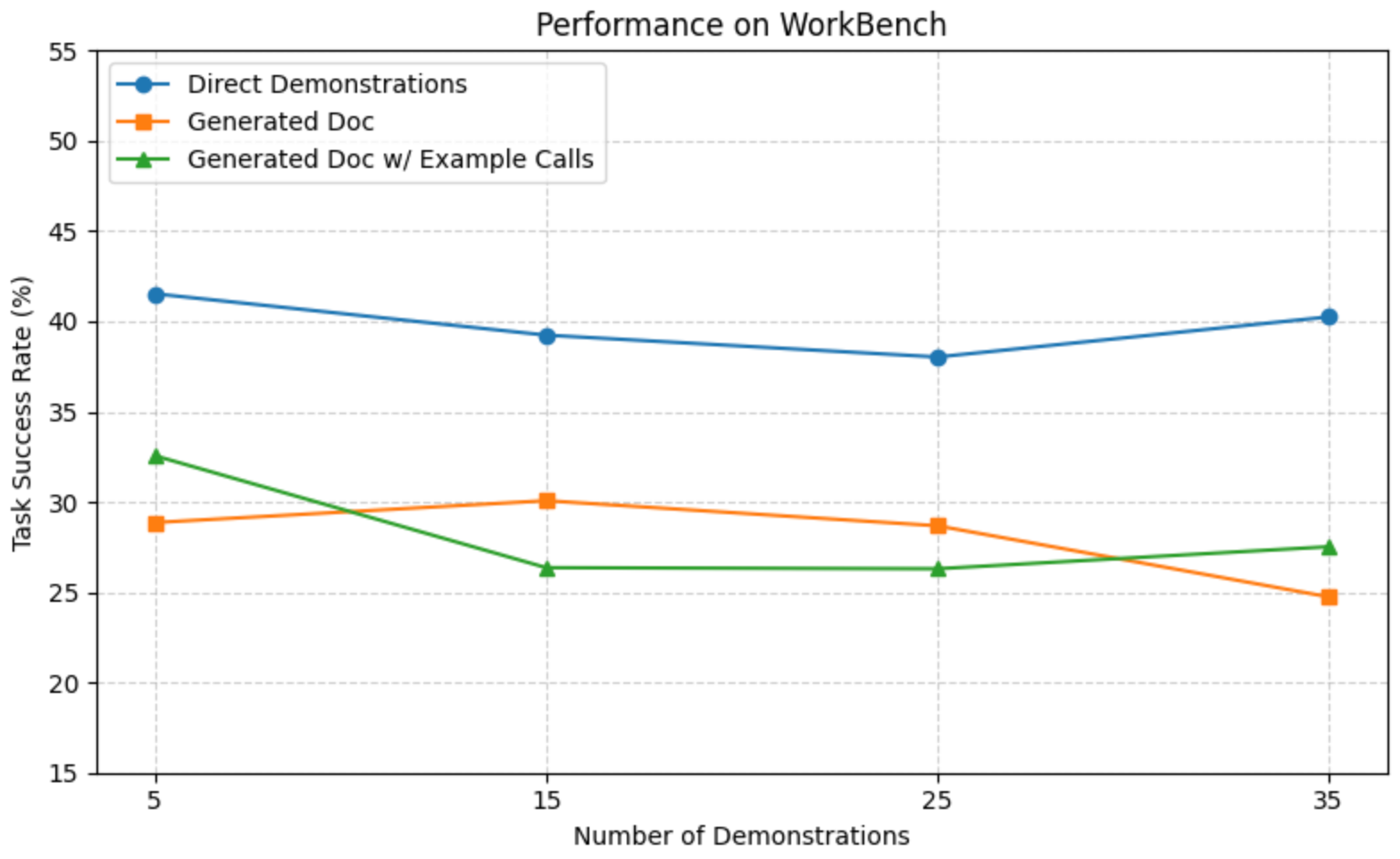
Degradation when Increasing Number of Demonstrations.
In Figure 3 we ablate on the number of demonstrations using the WorkBench dataset, and we see slight performance drop across all methods. For DxD, we hypothesize that this degradation is caused by increased context length. For GDEC, we see that as we increase the number of example calls attached to the generated doc, that the agent frequently makes unnecessary, repeated calls, suggesting that the increased example calls encourages the agent to believe that repetition is constantly needed for tasks. For GD, the drop occurs at 35 demonstrations. As explained earlier, generated documentation for WorkBench APIs would hallucinate needing timezone information in the time_min and time_max parameters, which causes runtime failures. We notice that GD with 5 demonstrations would more likely, and correctly, say that the parameters are optional than with 35 demonstrations. Thus, the agent is more likely to hit a runtime error with GD-35 demonstrations than with GD-5 demonstrations.
Effect of Self-Exploration and LLM-Critiques

Figure 4 provides an example of an agent solving a WorkBench task to reply to an email. The judge correctly flags the first reply_email call as incorrect, as it was generated before doing search_email. For each call in the generated trajectory, the LLM-critique is added to the experience-based demonstration representing the call. These demonstrations are then used for the Direct Experience (DE) and Attach Guidelines (AG) methods mentioned above.
Misleading Error Messages from the Environment
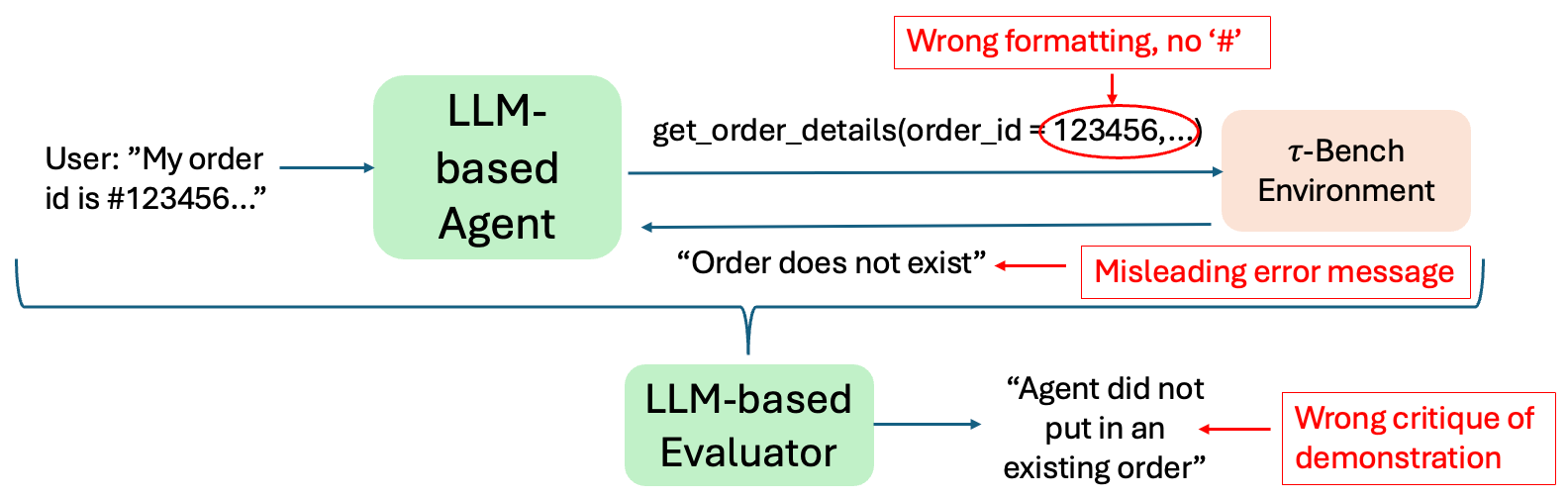
While Figure 4 shows a correctly generated critique, there are failure cases in this system that stem from misleading execution feedback. Figure 5 shows a representative case in our -Bench experiments where the agent incorrectly formats the order ID information by forgetting the ‘#’ at the beginning. The pre-defined get_order_details API of the environment then returns the message “Order does not exist”, rather than signaling to the agent that the order ID is improperly formatted. This misleading error message causes both the LLM-based agent and evaluator to believe that the order does not exist in the first place.
This error from the LLM-based evaluator also propagates to the generated guidelines, which summarize the critiques. In two trials, the guidelines actually said to remove the ‘#’ symbol! This error is reflected in Figure 6 where OD significantly outperforms DE and AG on τ-Bench. The ground-truth documentation was the only method that explicitly mentioned the need for the ‘#’ symbol. Therefore, we reran the AG experiment but hardcoded in every function that used the “order_id” parameter the following line: `THERE NEEDS TO BE A `\#' AT THE START OF THE ORDER ID. THIS IS MANDATORY. FOR EXAMPLE: ``\#W8732376'' IS VALID, BUT ``W8732376'' IS NOT!!!!''. Rerunning with this modification increased the average success rate over three trials from 10% to 49%.
Two takeaways from these results:
- This scenario highlights the importance of robust error handling in API functions for correct feedback and failure attribution. As using execution feedback becomes more prevalent for building tool-based agents [1, 2], having descriptive error messages can become critical in ensuring reliable deployment.
- For a group of APIs, there exist critical pieces of information that are crucial to learn for a high success rate. The order_id parameter is used in 7 out of 14 functions in τ-Bench. Therefore, knowing its correct formatting is imperative for most tasks in the benchmark.
Conclusion and Future Work
We presented a new perspective on learning API functionality from in-context demonstrations. This task reflects the realities faced by tool-based agents when documentation is missing, outdated, or incomplete. By leveraging both expert and experience-based demonstrations, supplemented with LLM critiques, our approach demonstrates that agents can bootstrap their understanding of APIs without repeated parameter updates. Our findings highlight both the promise and the pitfalls of this direction: demonstrations provide rich contextual cues, but the process is vulnerable to issues such as hallucinated documentation, misleading error messages, and the need for critical pieces of API knowledge (e.g., parameter formatting). Addressing these challenges will be crucial for deploying reliable agents in production settings.
Our study opens several promising avenues for future exploration:
- Active Exploration and Curriculum Learning: Rather than passively relying on expert or self-generated demonstrations, future work could incorporate active exploration strategies where agents query APIs with uncertainty-driven or curiosity-based methods to accelerate schema discovery.
- Multi-Agent and Collaborative Settings: Tool-based agents often operate in teams or pipelines. Studying how multiple agents can share and reconcile demonstrations (e.g., distributed API understanding) could enhance robustness and reduce redundant exploration.
- Robust Evaluation and Error Attribution: Misleading environment messages highlight the importance of reliable error attribution. Designing evaluators that distinguish between agent mistakes and environment-side errors would make guideline generation more reliable.
Ultimately, this work moves us a step closer to agents that can autonomously acquire tool-use capabilities in the wild, learning not from perfect manuals, but from the imperfect traces of usage left behind. Read more here
[1] Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." Advances in Neural Information Processing Systems 36 (2023): 68539-68551.
[2] Patel, Bhrij, Ashish Jagmohan, and Aditya Vempaty. "Learning API Functionality from Demonstrations for Tool-based Agents." Empirical Methods in Natural Language Processing (2025).
[3] Styles, Olly, et al. "WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting." First Conference on Language Modeling.
[4] Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. τ -bench: A benchmark for toolagent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045.
[5] Kung-Hsiang Huang, Akshara Prabhakar, Sidharth Dhawan, Yixin Mao, Huan Wang, Silvio Savarese, Caiming Xiong, Philippe Laban, and Chien-Sheng Wu. Crmarena: Understanding the capacity of llm agents to perform professional crm tasks in realistic environments. Nations of the Americas Chapter of the Association for Computational Linguistics (2025)
[6] Qian, Cheng, et al. "Toolrl: Reward is all tool learning needs." arXiv preprint arXiv:2504.13958 (2025).
[7] Li, Xuefeng, Haoyang Zou, and Pengfei Liu. "Torl: Scaling tool-integrated rl." arXiv preprint arXiv:2503.23383 (2025).
More From the Journal

The Next Frontier of Web Automation: Supercharging AI Agents with Web Domain Insights

Building GenAgent: A Journey Through Reliable Code Generation
