Trust by Design: Our UX Principles for Building Trustable Data Agents
AI agents are rapidly evolving. Code generation has emerged as the first truly impactful use case: agents can take natural language instructions and generate end-to-end applications with remarkable speed. Data analysis is an adjacent frontier where AI agents promise equally significant impact. Modern data agents can connect directly to Excel files, operational databases, and data warehouses like Snowflake. They can query data, perform statistical analysis, generate charts, and summarize insights in seconds. On the surface, this looks like an undeniable productivity win. Yet despite this promise, skepticism around AI-driven data analysis remains high.
That skepticism exists for good reason. Data agents are fundamentally different from agents that write code for application development, and applying the same expectations and UX patterns can be dangerous. There are several key differences:
a) Data work is judgment-heavy
Even seemingly standard metrics such as “monthly active users,” “revenue,” or “churn” carry nuanced, domain-specific interpretations that vary across organizations. Agents must navigate ambiguous definitions, implicit business logic, and often incomplete context. Seemingly small choices around aggregation, filtering, and granularity can materially change results, and minor differences in how business definitions and logic are applied, can drastically shift outcomes. As a result, answers can be technically correct yet materially misleading.
b) There is no such thing as “almost correct” data analysis
In agentic software development, users are often satisfied if an agent delivers 90–95% of a working solution, with the remaining gaps addressed through testing, iteration, and QA. Data analysis does not work this way. An analysis is only correct if it is both technically accurate and aligned with business semantics. A calculation may follow all the standard rules and produce mathematically correct results, but if it misinterprets business definitions, key metrics, or uses inconsistent assumptions, it is still incorrect in the context of the organisation. When data agents are used directly by business leaders or executives, there may be no safety net to catch mistakes. Even small errors, hidden assumptions, or misinterpretations can influence decisions and carry significant business risk.
c) Trust depends on process visibility, not just output quality
In data analysis, users do not trust results simply because they look polished or plausible. Trust is built by understanding how conclusions were reached: what filters were applied, which assumptions were made, where ambiguity existed and how they were resolved. Without visibility into the analytical process, even high-quality outputs can feel like black boxes.
These differences make one thing clear: data agents cannot be designed like general-purpose AI assistants or coding agents. They require a UX that foregrounds judgment, transparency, collaboration, and accountability—by design, not as an afterthought.
A trustworthy data agent does more than return a polished and plausible sounding answer. It must explain its reasoning, surface uncertainty, invite collaboration, and make its decisions inspectable and reusable. In practice, this means designing agents that think out loud, partner with humans when needed, and leave a clear trail of how conclusions are reached.
In this post, we outline our five non-negotiable UX principles for building trustable data agents—agents that users can rely on not just for speed, but for clarity, accountability, and transparency.

1. Think Aloud – “See the agent’s thought process as it happens”
The concept of “Think Aloud” originates from human usability studies, where participants verbalize their thoughts while performing a task—sharing observations, intentions, questions, and uncertainties as they occur. This gives researchers insight into human problem-solving, revealing reasoning, misunderstandings, and decision points that would otherwise remain hidden.
While coding agents like Cursor and Claude Code display intermediate reasoning to show progress or assist with debugging, these messages are primarily informative. In contrast, for data agents, Think Aloud is non-negotiable for trust. Every intermediate message must be carefully designed to build confidence, surface ambiguities, and make the agent’s judgment visible, because users cannot rely on outputs without understanding the reasoning behind them. Thoughtful UX design of the intermediate messages itself is essential.
Not all intermediate messages are equally useful. To effectively build trust, the agent must prioritize observations that directly inform the user, highlight ambiguity, and surface key reasoning and decisions—rather than dumping every calculation or statistical artifact.
Complex data analysis tasks can span seconds to minutes, making this the most critical window for building user trust. Using progressive disclosure, the agent surfaces information incrementally, showing what is most relevant at each stage without overwhelming the user. Expressed in domain-specific language, this running commentary gives users a clear, digestible view of the process, helping them maintain common ground, catch issues early, and intervene when necessary.
When done correctly, Think Aloud transforms the data agent into a transparent, collaborative partner- building confidence, supporting learning, and reinforcing trust throughout the analysis.
A demo of Data Agent Thinking Aloud
2. Collaborate - Shape the Analysis together with user
Trustworthy data agents don’t operate in isolation—they know when and how to involve users in the analytical process. Collaboration is not about repeatedly asking for confirmation; it’s about recognizing moments where human judgment meaningfully improves outcomes. These moments often arise around ambiguous decision points, incomplete context, competing interpretations, or choices that depend on business intent rather than statistical correctness.
Instead of silently resolving these decisions as current data agents tends to do, a partnering agent surfaces the uncertainty, explains why a choice matters, and invites the user to steer the analysis. This can take many forms: asking the user to clarify intent, presenting alternative paths with trade-offs, or pausing to confirm that an emerging direction aligns with expectations. The key is that the agent remains forward-moving while creating low-friction opportunities for intervention.
When done well, collaboration feels natural and proportional. The agent does not defer every choice to the user, nor does it lock them out of critical decisions. Instead, it maintains momentum while keeping humans in control of judgments that affect meaning, interpretation, and business alignment. This shared ownership of the analysis helps prevent subtle errors, ensures common ground, and builds confidence in the results. When the agent acts as a true collaboration partner, the user does not simply receive an answer. They help shape it.
A demo of data agent actively collaborating with the user
3. Transparent Assumptions : Surface all assumptions. No hidden decisions.
Every data analysis rests on assumptions, whether they are stated explicitly or not. Some are technical, such as how missing values are handled or which time window is considered. Others are analytical, like choosing a particular aggregation level, threshold, or outlier treatment. Still others are semantic, tied to business definitions and interpretation. These assumptions are unavoidable, but when they remain implicit, they become one of the biggest sources of mistrust in data analysis.
A trustworthy data agent actively detects where assumptions are being made. These moments often appear when the data does not uniquely determine a path forward. For example, when multiple filters could apply, when grouping levels could be interpreted in different ways, or when business logic is incomplete or inconsistent. Instead of silently resolving these choices, the agent treats them as first class artifacts of the analysis. While collaboration allows users to actively guide decisions in real time, surfacing assumptions at the end ensures that nothing is left hidden, even after the analysis completes.
As the analysis unfolds, the agent tracks assumptions and assesses their potential impact on results. At the end, assumptions should be explicitly surfaced to the user, not buried in code or inferred from outputs. This can take the form of a clear, structured summary that explains what was assumed, why it was reasonable in context, and how sensitive the results are to each choice. Crucially, these assumptions should remain open to challenge. Users must be able to question them, request alternative scenarios, or rerun the analysis under different conditions.
When assumptions are visible and inspectable, users gain context and control. They can see what the agent believed, evaluate the impact on the results, and decide whether to intervene or explore alternatives. By making assumptions explicit, the analysis becomes both more reliable and more collaborative.
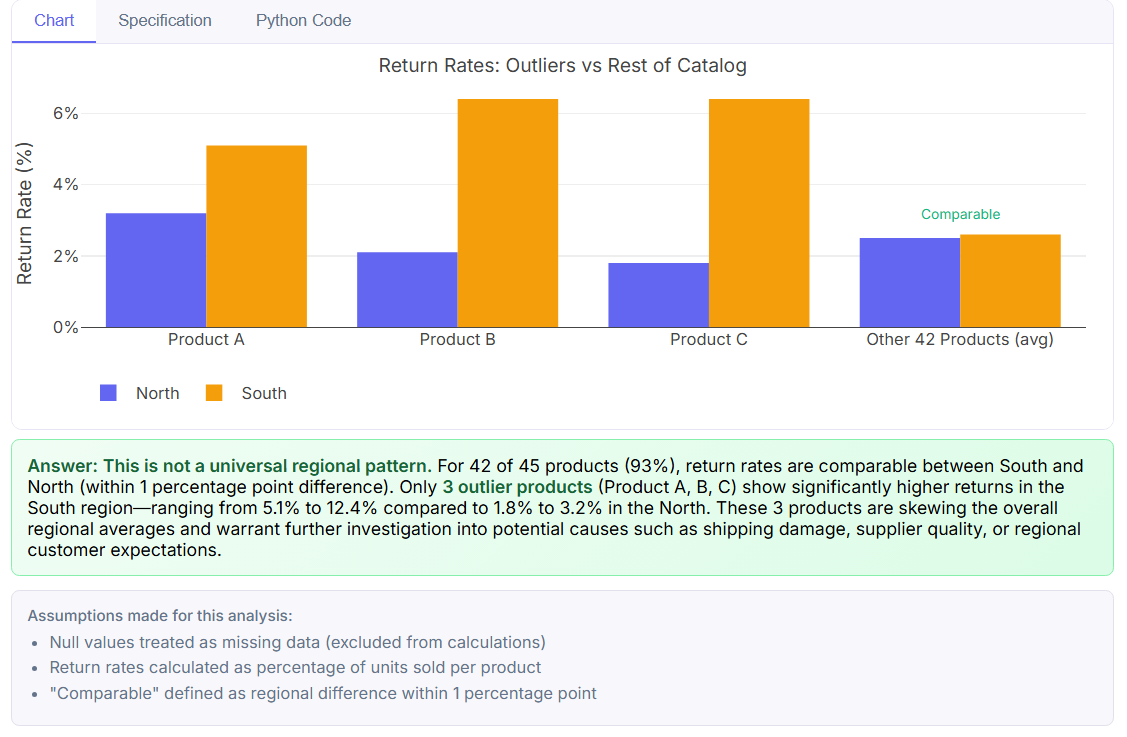
4. Explainable Specification: See logic behind every insights, in words and code.
Every analysis artifact an agent produces—whether a chart, a table, or a textual summary—represents a chain of transformations, filters, and calculations. For users, especially in complex datasets, this chain is often invisible. Without visibility, even technically correct results can feel like black boxes, raising questions about validity and reproducibility.
Explainable Specifications address this by pairing every insight with a clear description of how it was generated, in both natural language pseudo-code and actual code. Non-coding users can read a step-by-step account of what the agent did, while technical users can see the underlying queries or scripts. This dual representation ensures that everyone can audit, validate, and learn from the analysis, bridging the gap between transparency and usability.
Beyond trust, explainable specifications support reproducibility and reuse. Once a workflow is validated, its steps can be saved, shared, and rerun on similar datasets, reducing repeated effort and standardizing analysis across teams. They also serve as living documentation, capturing business logic, assumptions, and operational choices in a format that is both human-readable and machine-executable.
By making the “how” of analysis explicit, explainable specifications transform each insight from a static output into a transparent, auditable artifact, empowering users to verify results, adapt workflows, and confidently make decisions based on the agent’s work.
Specifications: in words and code
5. Trusted Templates :Save human verified workflow for reuse
Explainable specifications make every insight transparent, but the value multiplies when validated workflows can be saved and reused. Trusted Templates take these auditable steps and lock in human review and verification, creating a set of standardized, dependable analysis patterns.
Once a workflow has been verified, it can be applied to similar datasets or recurring tasks, reducing repeated effort, ensuring consistency, and embedding best practices across teams. For example, a validated revenue analysis or churn calculation can become a template that preserves business rules, assumptions, and transformation logic, so that future analyses start from a proven, trusted foundation.
Templates also act as living documentation. They capture not just the steps of the analysis, but the decisions, assumptions, and business logic that went into it, making it easier for new team members to understand past work and for auditors to verify compliance. When combined with Explainable Specifications, Trusted Templates ensure that human insight and judgment are preserved, while enabling agents to execute analyses reliably, efficiently, and consistently.
In short, Trusted Templates turn one-off analyses into repeatable, auditable workflows, closing the loop between transparency, collaboration, and trust.
Conclusion
Building trustable data agents requires more than speed or accuracy; it requires transparency, collaboration, and reproducibility at every step of the analysis. By designing agents that think aloud, partner with users, surface assumptions, explain their steps in words and code, and preserve human-verified workflows as trusted templates, Emergence is creating tools that users can rely on confidently, not just for results, but for understanding, control, and accountability.
These five design principles are the foundation of our approach to trust by design. At Emergence, trust is not an afterthought—it is built into every interaction, every step, and every insight.