
State of the Art Results in Agentic Memory
Language models have limited attention to spread over their context windows. This makes them surprisingly weak at interactions involving long or many conversations or documents. To address the document problem, the typical approach is to employ a variety of retrieval augmented generation (RAG) techniques. Such techniques can also be applied to conversational data, but there are differences, such as who said what and when, that are beyond typical RAG. Folks at the Tencent AI Lab created a long memory benchmark (LongMemEval) to evaluate question answering performance given reasonably long conversational histories. In this benchmark, a conversational history consists of approximately 40 conversations with each conversation having over a dozen turns on average. 500 turns is not very much in terms of a conversational history, but it is significantly more than prior conversational benchmarks, as shown by the authors:
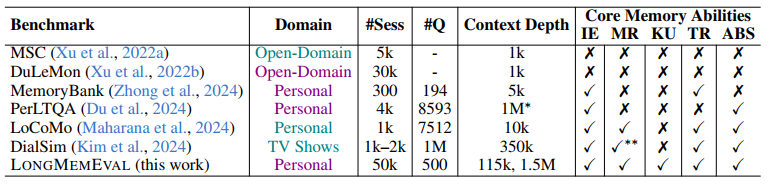
LongMemEval has 500 benchmark items, each a question of some type, an answer (or a rubric), and a “haystack” of conversations. Conversations are reused and mixed in different ways across items. A conversation occurring at one time in one haystack commonly occurs on different dates in other haystacks. The table above shows that haystacks from the S subset of the full LME dataset correspond to roughly 115,000 tokens in a language model’s context window.
To demonstrate the limitations of language models in longer context, the authors found that GPT-4o1 achieved only 58% accuracy2 when given the full haystack (i.e., ~115,000 tokens). Subsequently, in a paper by Zep, providing the full haystack to GPT 4o benchmarked at 60% with over 30 second latency (which is due to the large context window, not generation).
· Our experiments found GPT 4o 64% accurate with average latency around 10.4 seconds.
· We also tried providing full haystacks to Open AI’s O3 model which has “thinking”, unlike GPT 4o. We found O3 to be 76% accurate with an average latency of around 19 seconds.
In the same paper, earlier this year, Zep published results showing 71% accuracy and median latency around 3.2 seconds. That latency is more viable than the full context results and the accuracy is above GPT 4o. It should be noted that Zep achieved that superior accuracy by limiting the context window to more pertinent turns of conversation than full haystacks. In their January 22, 2025 blog post, Zep describes this as “The New State of the Art In Agent Memory”.
Like Zep, we have a flexible memory architecture which we have designed to address a wide variety of agentic use cases, including the obvious cases in document-centric RAG, multimedia, and conversations. The architecture provides and allows for various embeddings, n-spaces, relationships, etc. It combines embeddings and kNN techniques with relational databases and graph techniques.
The Zep paper describes an elaborate process, not terribly dissimilar from some of the techniques we employ when appropriate, to achieve their benchmark performance. We figured we might as well give it a go. Our detailed results are available here.
We started by summarizing each conversation, identifying episodes (a topic spanning some turns of the conversation with key takeaways), and facts (sentences broken down into detailed subjects, relations, objects, complements, and adjuncts). This breakdown of sentences allows us to build a semantic graph with continuous representations of each of its nodes and links, but as you will see we didn’t need to go that far to establish a new state of the art on LongMemEval...
In our first attempt, we took each question and retrieved a small, variable number of user turns using a moderately high threshold. Given the retrieved turns we identified the sessions containing those turns and provided GPT 4o with just the facts of their sessions. This first attempt had an accuracy of 64%, on par with providing the full haystack to GPT 4o.
Well, that was easy, but not good enough. We didn’t expect a great result here since we did not provide the language model with the actual turns of the conversations. We were pleasantly surprised that our fact extraction method worked as well on a standalone basis, however. In contrast, this blog post attributes Mem0’s failures on LME to its summarization losing important details. Our fact extraction didn’t lose much detail, but any extraction or summarization will definitely lose some. We expected this and to investigate the use of turns, as discussed below.
In this benchmark, the assistant often responds in a long-winded manner and the user often submits significant fragments of text (as in fragments of spreadsheets). The number of facts that can be extracted per session is therefore quite large. This is where either retrieval (facts are separately indexed in our memory) or reranking and filtering may be applied.
One peculiarity of LME is that facts extracted from a conversation cannot resolve temporal references (e.g., this Friday) to specific dates since the same conversation may be simulated as occurring on different dates in different haystacks. This doesn’t happen in real life!
In light of this, we precluded our fact extraction from resolving relative temporal references. For example, we left “this Friday” alone in the extracted facts rather than resolving it to specific date. In total, we extracted over 686,404 facts3 and 65,886 episodes from 19,829 conversations having 246,930 turns. We did not want to multiply this number by 2 orders of magnitude just for LME! We were pleased that GPT 4o did as well in resolving relative temporal references given the dates of conversations per haystack, however. It would do even better if the facts were grounded in time.
Before testing the combination of facts with retrieved turns, we pursued some other alternatives aimed at limiting the size of the context provided to the language model. After doing so, we had little motivation to leverage fact retrieval or filtering, as you will understand...
In one approach, we retrieved the top k turns (both user and assistant turns) and provided these to GPT 4o, asking it to generate pertinent facts from the retrieved turns, and then prompt GPT 4o with the retrieved turns and the generated facts to answer the question. Depending on the value of k, this 2-step method obtained accuracy in the 66-69% range.
In a second approach, we retrieved a variable number of user turns exceeding a moderate threshold, as previously, and then we determined the subset of conversations within a haystack containing those turns. Then we provided all turns of those sessions to GPT 4o. We found minor variations of this to be 76-78% accurate, a result which is on par with providing the full context to O3, a thinking model! We do a bit better on accuracy over 3 times faster using an order of magnitude fewer tokens. That’s not only viable for users but easy on the wallet.
In the paper introducing LongMemEval, the authors discuss a “chain of note” technique which they use in establishing baseline performance on the benchmark. So, we now introduced some more limited (i.e., faster) chain of thought techniques into the prompt. This resulted in accuracy in the 83-86% range with median latency around 5 seconds, which is above GPT 4o’s performance (82%) when given precisely the relevant turns of conversation! Apparently, a little more conversational context helps.4,5
We can do better, of course. There are questions we miss because the words in the question are not all that close (semantically) to the turn needed for accuracy. This is where having a continuous/latent knowledge graph helps quite a bit. But comparing our retrieval results with the “oracle” information provided by the LongMemEval authors, we find that straightforward techniques missed only a few pertinent turns impacting performance. So, we might get 5 or so more questions correct, but what’s the point?
Another handful of missed questions resulted from only retrieving user turns. When we retrieve from all turns we obtain 81-83% accuracy depending on various things, such as how we filter sessions and configure the chain of thought. We will apply some other techniques to realize more of the benefit of retrieving assistant turns with less of the distraction too many cause language models. The most common technique, which would improve our results in a variety of manners, would be to employ reranking.
Practically speaking, the ‘preference’ category of questions, for which there are rubrics rather than answers, is poorly defined and evaluated. This is where we get the lowest accuracy (around 70%). Extracting preference information from conversations and aggregating is the right way to go for this. Thus, we would expect extracted facts to improve performance here. Perhaps, if someone tops us with something more interesting than merely performance hacking, we’ll give it a further go!
Our next objective is a more enterprise-focused benchmark requiring memory, especially memory for crafting agents from enterprise documents and conversations with and among team members spanning the agentic lifecycle (i.e., years).
- In all cases herein GPT-4o refers to the version from August 6, 2024.
- This a weighted average of accuracy per type of question using the number of said type as its weight.
- These facts involve 648,908 nominals, 556,592 relations, and 165,769 roles (before clustering and graphing).
- The benchmark could be easily improved in this area, but we are reporting without any alteration.
- Apparently, Zep found the same thing as they mention including the assistant turn following retrieved user turns in their paper.
More From the Journal

Trust by Design: Our UX Principles for Building Trustable Data Agents

Agentic AI for Enterprise Needs Much More than LLMs
