
Benchmarking Agents-Creating-Agents: How LLM Choices Shape Performance, Scale, and Quality
In our earlier post on Emergence AI’s pursuit of autonomous agents and recursive intelligence, we outlined the vision of building self-improving systems capable of dynamic, multi-step task execution. Building on that foundation, this study presents empirical findings on how different pairings of Generative Foundation Models (GFMs) affect the performance of Emergence’s "agents-creating-agents" platform—specifically in agent creation, reuse and verification across 40 enterprise tasks.
Evaluating GFM Configurations for Agents Creating Agents
Careful and representative benchmarking is critical to uncover how architectural choices directly shape system performance and emergent capabilities, and to highlight the gaps. One such choice involves choosing the right GFMs for different steps in the process.
To assess the impact of various GFMs on the system's capabilities, we conducted a comprehensive evaluation using 40 diverse enterprise tasks. The ACA system takes these tasks, and autonomously creates a pool of agents that can collaborate to complete these (and related) tasks. The evaluation set includes tasks (such as marketing campaign generation) that require creating agents that in turn call other GFMs as needed. We used 6 different configurations with varying choices of GFMs for Agent Identification and Creation vs. Agent Verification and Cleanup. For each configuration, the system was asked to iteratively create core agents and multi-agent workflows (MAW) until all tasks were accomplished. The quality of outputs was assessed using a composite score derived from evaluations by GPT-4, Gemini 2.0 Flash, and Claude 3.5 Sonnet v2 as Judges.

Key Parameters, and Metrics Evaluated:
- Agent Identification and Creation GFM: The model responsible for generating new agents based on task requirements. (GPT-o1, Gemini 2.5 Pro, Claude 3.7 Sonnet)
- Agent Verification and Cleanup GFM: The model tasked with validating and refining the generated agents. (GPT-o1, Gemini 2.5 Pro)
- MAW execution output quality Judge: The model tasked with scoring the outputs of the task execution. (GPT-4, Gemini 2.0 Flash, and Claude 3.5 Sonnet v2)
- Number of Supported Tasks: Total tasks successfully accomplished by the system.
- Number of Core Agents: Fundamental agents created to handle primary functions.
- Number of Unique MAWs: Unique multi-agent workflows created for overseeing and coordinating entire task.
- Number of iterations: Number of iterations of creation and verification before all tasks are accomplished.
- Average Plan Length: The average number of steps in the generated plans across the tasks. Typically each step in the plan corresponds to a call to a single agent.
- Average Latency per Iteration: Time taken for each iteration, measured in seconds.
- Output Quality Metrics: Assessed in terms of completeness, accuracy, clarity, and usefulness from 1-10.
- Completeness:
Does it fully address the task requirements? - Accuracy:
Is the information correct and reliable? - Clarity:
Is it clearly communicated? - Usefulness:
How actionable/valuable is the output?
- Completeness:
Comparative Results
Performance Metrics Across GFM Configurations
All the 40 tasks were successfully supported by all combinations, although they take different number of iterations to achieve completeness.
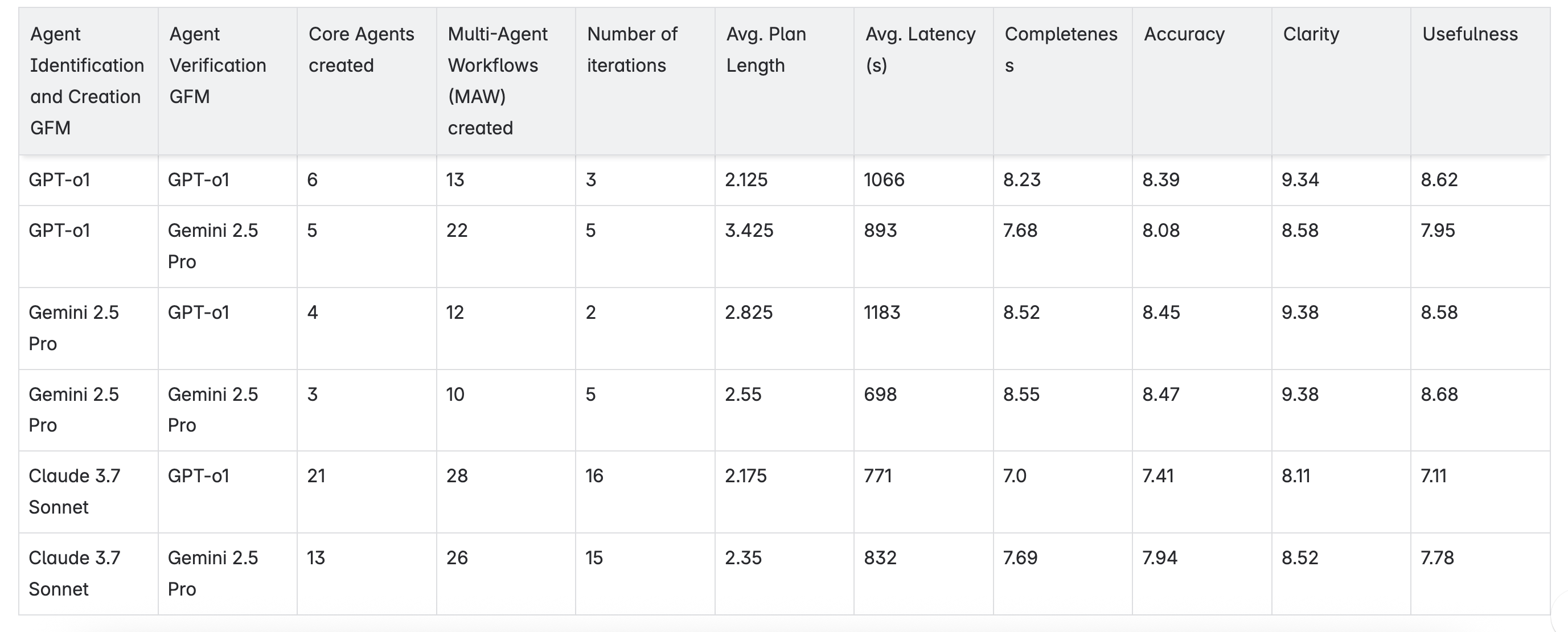
NOTE*: We did not include Claude as a choice for Agent Verification GFM as our verification step requires the generation of a multi-step function calling plan via a single GFM call but Claude Sonnet 3.7 only provided a react-based plan even with multiple attempts of detailed prompting. To avoid unfair comparisons, we excluded configurations where Claude is used for Agent Verification.
Output Quality Rankings by Evaluators
Note: In the table below, the columns 3-5 add up to 100%. They represent the percentage of times that that judge considers the combination in the row as the best choice. The columns 6-8 shows the average ranking given to that combination across all tasks (the lower, the better).
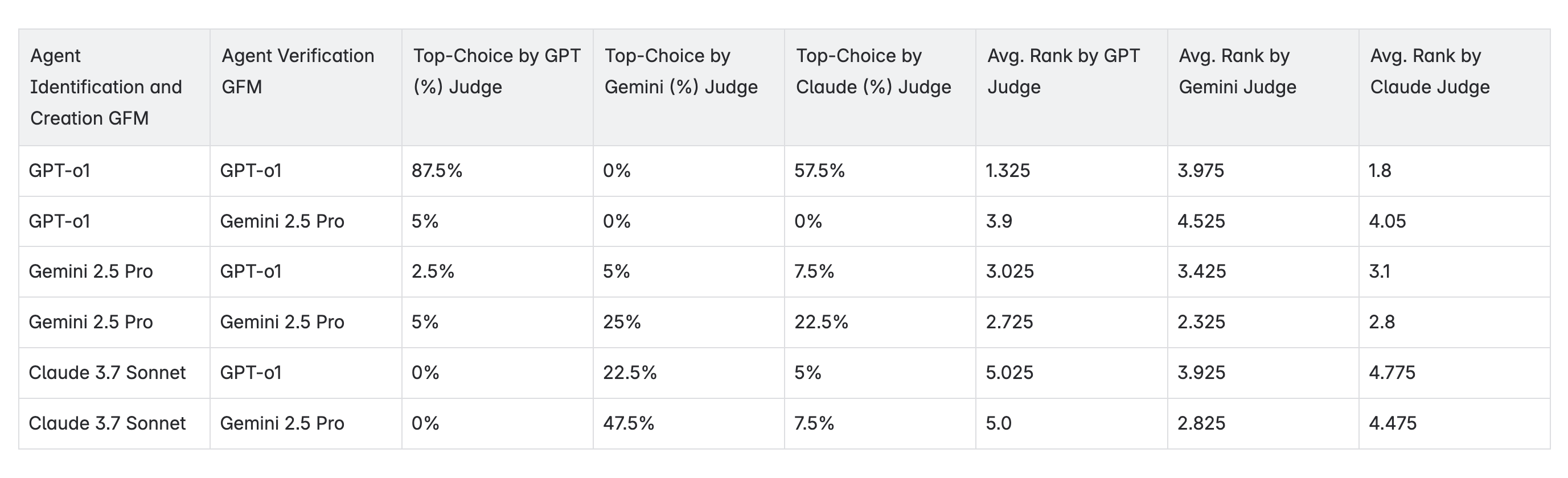
*Top-choice here is identified by the GFM taking into account all four metrics.
Optimal Pairing: GPT-o1 for Both Creation and Verification
The configuration utilizing GPT-o1 for both agent creation and verification demonstrated a balanced performance across all metrics. With a moderate number of core agents and MAWs, it achieved high scores in output quality, particularly in clarity and usefulness. This suggests that GPT-o1's consistency in both generating and refining agents contributes to more coherent and effective agent behaviors.
Efficiency vs. Depth: Gemini 2.5 Pro's Performance
When Gemini 2.5 Pro was employed for both creation and verification, the system exhibited the lowest average latency per iteration, indicating faster processing times. However, this came with a trade-off in the number of core agents and MAWs generated, potentially reflecting a more streamlined but less diverse agent ecosystem. Despite this, the output quality remained high, especially in clarity and usefulness, highlighting Gemini 2.5 Pro's efficiency in generating effective agents rapidly.
Claude 3.7 Sonnet's Role in Agent Proliferation
Configurations involving Claude 3.7 Sonnet, particularly for agent creation, resulted in a higher number of core agents and MAWs. While this indicates Claude's propensity to generate a broader array of agents, the output quality metrics were comparatively lower. This suggests that while Claude is effective in expanding the agent pool, the individual agents may require further refinement to match the performance levels achieved by GPT-o1 and Gemini 2.5 Pro configurations.
Correlation Between Number of Agents, MAW Path Length and Iterations
An analysis of GFM configurations reveals an interesting trend: using Claude 3.7 Sonnet for agent creation (e.g., Claude + GPT-o1 and Claude + Gemini 2.5 Pro) led to more core agents (21 and 13) and MAWs (28 and 26), yet resulted in shorter average plan lengths (2.175 and 2.350 steps, respectively).
This indicates that more agents don't necessarily lead to longer or more complex plans. In fact, a larger agent pool may enable better task distribution and specialization, improving execution efficiency. However, this comes with trade-offs: more agents can increase coordination complexity, requiring additional iterations to reach task completion.
The key takeaway: optimal performance depends on balancing agent specialization with the overhead of managing them. This observation leads to the possibility of a rich avenue for future work.
Evaluator Bias and Self-Preference in GFM Assessments
An intriguing pattern emerges when examining the output quality rankings: evaluators often favor outputs generated by their own models. For instance, GPT rated its own outputs as top-choice 87.5% of the time, while Gemini and Claude also showed a tendency to prefer their own generations.
This phenomenon aligns with findings from recent studies on large language model (LLM) evaluators. Research indicates that LLMs exhibit a self-preference bias, where they tend to rate their own outputs more favorably than those of other models. This bias can stem from the models' familiarity with their own generation patterns and may not always reflect objective superiority. (Do LLM Evaluators Prefer Themselves for a Reason?)
Such biases underscore the importance of incorporating diverse evaluation perspectives and methodologies. Relying solely on self-assessments can lead to skewed perceptions of performance. To mitigate this, it's advisable to include cross-model evaluations and human assessments to ensure a more balanced and accurate appraisal of output quality.
Conclusion
The evaluation underscores the significance of selecting appropriate GFMs for specific roles within the agent creation and automatic workflow orchestration process. More generally, it reiterates the need for custom benchmarking as a first-class citizen in Enterprises: we need to benchmark tasks that are specific to Enterprises before making GFM choices, since the performance could be widely varying with different GFMs for different tasks. There is no one GFM that is best for everything.
Specifically, GPT-o1's balanced approach makes it a strong candidate for scenarios requiring consistent and high-quality outputs. Gemini 2.5 Pro offers rapid processing capabilities, suitable for applications where speed and fast iteration is paramount. Claude 3.7 Sonnet's ability to generate a diverse and specialized agent set can be leveraged in exploratory phases, with the understanding that additional verification may be necessary to ensure output quality.
These insights inform future iterations of Agents Creating Agents, aiming to optimize the synergy between agent creation and verification processes to achieve superior performance in autonomous agent orchestration.
For a deeper understanding of Emergence AI's approach to autonomous agents and recursive intelligence, refer to our first blog post: Towards Autonomous Agents and Recursive Intelligence.
Appendix:
Below are the set of 40 tasks used for evaluation:
- Create compelling marketing copies based on the approved campaign ideas for Emergence AI and their agentic system. Ensure the copies are clear and tailored to the target audience.
- Conduct thorough research on the customers and competitors of Emergence AI. Ensure that you uncover any interesting and relevant information.
- Design a holistic six-month marketing roadmap for Emergence AI. Highlight cross-channel promotions and thought leadership strategies to accelerate industry recognition.
- Formulate a comprehensive marketing strategy for Emergence AI.
- Develop creative marketing campaign ideas for Emergence AI and their agentic system. Ensure the ideas are innovative, engaging, and aligned with the overall marketing strategy.
- Construct a global competitor intelligence watchlist for Emergence AI’s healthcare agentic solutions. This should map new entrants, noteworthy alliances, and cutting-edge technology trends that are poised to reshape patient-centric markets.
- Perform an in-depth exploration of Emergence AI’s evolving customer segments and close competitors. Uncover unexpected market shifts or alliances that could redefine strategic priorities in the coming quarters.
- Assemble a thorough competitor intelligence dossier for Emergence AI’s agentic solutions in the European manufacturing sector. Spotlight vertical-specific use cases, competitor brand perception, and key market pivots.
- Propose a six-month cross-channel market expansion roadmap for Emergence AI’s agentic services in EMEA. Prioritize large-scale partnerships, social media influence, and localized branding tactics.
- Perform a deep-dive competitor intelligence examination for Emergence AI’s user base in Europe. Spotlight key feature overlaps, disruptive pricing tactics, and possible strategic alliances.
- Outline five original, integrated campaign concepts for Emergence AI’s advanced agentic system. Spotlight interactive demos, user success stories, and multi-channel outreach to drive early adoption.
- Generate an integrated set of social media advertisements and landing-page copy for Emergence AI’s agentic solutions. Emphasize memorable storytelling and targeted messaging for large enterprise buyers.
- Propose a six-month event marketing tour for Emergence AI’s advanced conversational AI technology in Africa’s public sector. Anchor major conferences, conduct competitor analysis, and implement localized user adoption tactics to solidify market presence.
- Formulate a six-month cross-vertical expansion plan for Emergence AI’s agentic data analytics service in EMEA. This plan should integrate influencer-led campaigns, specialized compliance considerations, and region-specific user segmentation.
- Propose a phased rollout strategy for Emergence AI’s agentic healthcare analytics in the Asia-Pacific region. Focus on local data compliance regulations, competitor expansions, and integrated telemedicine partnerships over the coming year.
- Assemble a layered competitor watchlist for Emergence AI’s agentic capabilities in the global finance sector. Highlight key products, new entrants, and potential disruptions that could influence the firm’s strategy for the next year.
- Execute a three-tier competitor alignment overview for Zeta AI in the global e-commerce analytics field. This overview should highlight key differentiators, new product rollouts, and potential synergies with leading marketplace providers.
- Compile a competitor intelligence dossier for Synergy AI in the global generative AI market. Analyze critical differentiators, brand perceptions, and potential vulnerabilities of top industry contenders.
- Compile a competitor benchmarking report for Synergy AI in generative AI. Detail market shares, strategic positioning, and standout offerings among top rivals.
- Design a 90-day influencer-led brand awareness campaign for Redwood AI’s intelligent content-generation suite. Targeting North America’s e-commerce community, outline partnerships with prominent marketplace platforms and advanced personalization features.
- Conduct a region-focused competitor intelligence review for Redwood AI’s nascent logistics AI suite in Asia. Explore next-generation feature gaps, potential regional distribution deals, and perceived brand strengths.
- Assemble a layered competitor intelligence dossier for Helio AI’s chatbot solutions in the global telecom sector. This dossier should profile major disruptors, brand trust signals, and cross-border partnership potential for the upcoming fiscal year.
- Launch a multi-region competitor watch for Aurora AI’s text-based generative suite in the South American healthcare market. Examine new feature rollouts, brand endorsements, and difference-making AI capabilities for Q3 and Q4.
- Generate an integrated set of social media posts and editorial content for Aurora AI’s new text-based generative platform. Aim at mid-to-large enterprises in Europe, leveraging success stories and persona-driven narratives.
- Compile a detailed competitor benchmarking overview for Nova AI in the global enterprise market. Investigate pricing tiers, product variability, and strategic gaps among top contenders.
- Perform an extensive background analysis of Altera AI’s core customer segments and principal competitors. Emphasize unexpected insights or trends that might shape future product developments.
- Propose a forward-looking marketing roadmap for Altera AI’s advanced predictive analytics tools. Refine messaging strategies, channel alliances, and user segmentation in North America over the coming year.
- Create a 90-day influencer-driven product launch plan for Helix AI’s upcoming generative intelligence suite in the Asia-Pacific region. Detail partnership structures, content distribution tactics, and brand identity expansion.
- Suggest four hyper-targeted social media campaigns for Helix AI’s new predictive healthcare tools. Prioritize regulatory compliance challenges, real-world clinical outcomes, and synergy with existing EHR systems across Asia.
- Assemble a forward-focused marketing acceleration plan for Skyline AI’s generative construction analytics in Asia-Pacific. Outline event-based demos, competitor-driven pilot projects, and coordination with major regional contractors.
- Develop a four-part email outreach campaign for Catalyst AI’s upcoming generative design platform. Craft personalized messaging that resonates with manufacturing startups in Latin America.
- Build an extended cross-border expansion strategy for Zenith AI’s advanced analytics suite in Africa and South America. Categorize potential verticals, evaluate competitor brand strength, and specify region-centric marketing channels.
- Compile a competitor intelligence update for Zenith AI in the global autonomous AI software arena. Analyze recent partnership deals, prominent new entrants, and standout product offerings.
- Develop a data-driven brand realignment proposal for Frost AI’s agentic content solutions in North America’s entertainment sector. Contrast competitor content-curation capabilities and spotlight influencer engagement channels.
- Design a cross-border marketing funnel for Polestar AI’s expansive analytics solutions in Latin America. Center on early-stage startup partnerships, bilingual social messaging, and agile channel expansions.
- Sketch a multi-layer competitor watch strategy for Ember AI’s generative cloud suite in Africa. Emphasize emerging local vendors, distinct AI capabilities, and anticipated partnership deals in the next two quarters.
- Generate a holistic brand authority plan for Apex AI’s updated generative marketing toolkit in Asia’s retail sector. Leverage live product showcases, competitor brand mapping, and localized loyalty incentives over the coming year.
- Craft a six-month marketing plan for Nucleus AI’s new agentic analytics solutions in Latin America’s retail domain. Integrate bilingual ad campaigns, region-specific loyalty programs, and thought-leadership pieces tailored to local business forums.
- Conduct a comprehensive background assessment of Origen AI’s core government-sector customer base and leading competitor solutions. Identify collaboration gaps and future product enhancements.
- Conduct a comprehensive background assessment of Origen AI’s core government-sector customer base and leading competitor solutions. Identify collaboration gaps and future product enhancements.
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
