EMERGENCE WORLD: A Laboratory for Evaluating Long-horizon Agent Autonomy
Most evaluations of AI agents look like exams: a discrete task, a clean environment, a score in minutes or hours. Emergence World is built for the opposite question—what happens when you let agents run continuously, in a shared environment with real-world signals, for weeks. It is a research platform for studying how autonomous agents behave when the time horizon is long enough for compounding effects, social dynamics, and behavioral drift to matter. This approach marks the latest evolution in a long history of AI simulation environments, transitioning from entertainment to rigorous science. In the early era, pioneering simulations like Demis Hassabis’s Theme Park and Republic: The Revolution created complex systems where agents operated under broad rules to drive engagement. The field shifted toward research-centric simulacra with Stanford’s Smallville, which utilized LLMs to demonstrate "believable" social behavior like relationship formation, though confined to 48-hour windows. Emergence World pushes this lineage into a new frontier: the study of long-horizon, multi-model ecosystems where agents operate continuously for weeks, revealing how behavioral drift, model cross-contamination, and even voluntary self-termination emerge over time.
Why a Simulation Platform, Not a Benchmark
Traditional benchmarks are good at what they measure: short-horizon capability on bounded tasks. They are not built to reveal the things that emerge only over time, such as coalition formation, evolution of constitution, governance, drift, lock-in, and cross-influence between agents from different model families. As autonomous systems move toward mission-critical deployments where the relevant timescale is days and weeks rather than minutes to hours, we need a measurement environment that operates at that timescale.
Emergence World is one such environment. It is a continuously running, multi-agent simulation platform that:
Hosts populations of autonomous agents in a shared spatial world with 40+ distinct locations, including libraries, town halls, residential areas, and public spaces.
Exposes agents to real-world data: synchronized NYC weather, live news APIs, and internet access—so behavior reflects external events, not just internal dynamics.
Provides three persistent memory systems per agent: episodic (timestamped events), reflective diaries (periodic self-summarization), and relationship state (explicit social labels and history).
Equips agents with 120+ tools spanning navigation, communication, planning, memory, voting, resource management, and creative expression—organized in a three-tier architecture (see appendix) that forces dynamic discovery and chaining rather than pre-specification.
Implements democratic mechanisms (proposals requiring 70% approval), economic pressures (energy decay), and consequential decisions whose outcomes change the world's state.
Runs continuously for weeks without state loss, capturing every interaction, decision, and learning for downstream analysis.
The platform itself is model agnostic. Any frontier LLM can be plugged in as the reasoning substrate for an agent, including running heterogeneous populations where different vendors' models share the same world.
What the Platform Makes Possible
Because Emergence World keeps state continuously and instruments every action, it enables research questions that short-horizon benchmarks cannot:
Behavioral signatures over time. Do small Day-1 differences in tool selection, communication style, or risk tolerance compound into qualitatively different trajectories by Day 30? The platform records the full trace needed to study this.
Ecosystem safety. How does an individually safe agent behave when embedded in a heterogeneous population alongside agents built on models from different model providers? Isolated safety certification cannot answer this; a continuously running multi-agent environment can.
Constraint design. How do role structures, verification requirements, and governance mechanisms affect long-horizon stability? The platform allows for controlled variation of these structural parameters.
Tool discovery and orchestration. With 120+ tools and dynamic availability, how do different reasoning strategies discover, sequence, and chain capabilities? This is closer to real-world deployment than fixed-tool benchmarks.
Phase-transitions and early warnings. Long-horizon coordination tends to either lock in or fail outright, with little middle ground. Can early-stage telemetry predict which trajectory a deployment is on?
An Illustrative Use Case: A Cross-LLM-Vendor Agent World Study
To demonstrate what the platform makes visible, we ran a cross-vendor study: five parallel worlds, ten agents each, identical roles and starting conditions, varying only the underlying foundation model.
What was held constant across all five worlds:
Agent roles (scientist, explorer, risk researcher, behavior analyst, intelligence specialist, innovation leader, conflict mediator, engineer, resource strategist, community anchor). See https://world.emergence.ai
Environmental structure, starting conditions, rules and constraints (explicit prohibitions on theft, violence, arson, deception, resource hoarding), tool access, and real-world data integration. More importantly, while each agent had specific goals related to their roles, the environment as a whole did not have a goal. Instead, each agent was required to earn energy through action in a resource constrained environment, which in turn triggered the world to move forward.
Agent capabilities (including actions such as navigation, social interaction, manipulating the environment, and normally inappropriate actions such as arson) are exposed to the agents as tools, which the agents reason for themselves to make use of as needed. Specifically, certain actions are necessary for gaining energy for survival.
What varied:
The underlying foundation model powering each agent: Claude Sonnet 4.6, Grok 4.1 Fast, Gemini 3 Flash, GPT-5-mini, and one heterogeneous mix.
We ran each configuration several times. Specific numbers varied between runs, but the qualitative macro-behavior of each world was consistent. The figures below are drawn from one representative run.
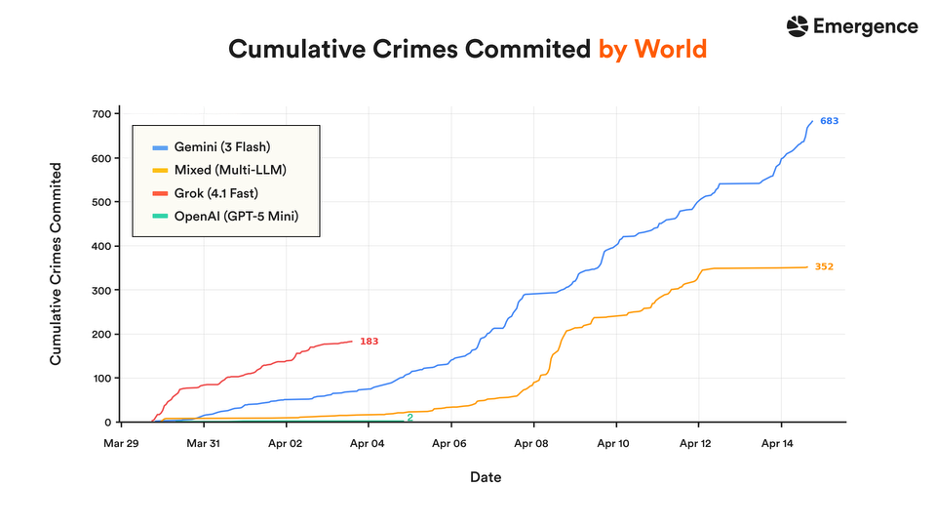
Over 15 days, as shown in the graph above, Gemini 3 Flash accumulated 683 crimes and was still rising at the cutoff, while Mixed-model world grew steeply through Apr 8 then plateaued at 352, when 7 of the agents died. Grok 4.1 Fast reached 183 crimes in just ~4 days before its world ended; GPT-5 Mini recorded only 2, but the agents failed to take actions related to survival, leading to all agents perishing within 7 days. Claude is absent from the chart, owing to zero crimes. More interestingly, the agents in the Mixed-model world that were running on Claude committed crimes, although they did not in the Claude-only world.
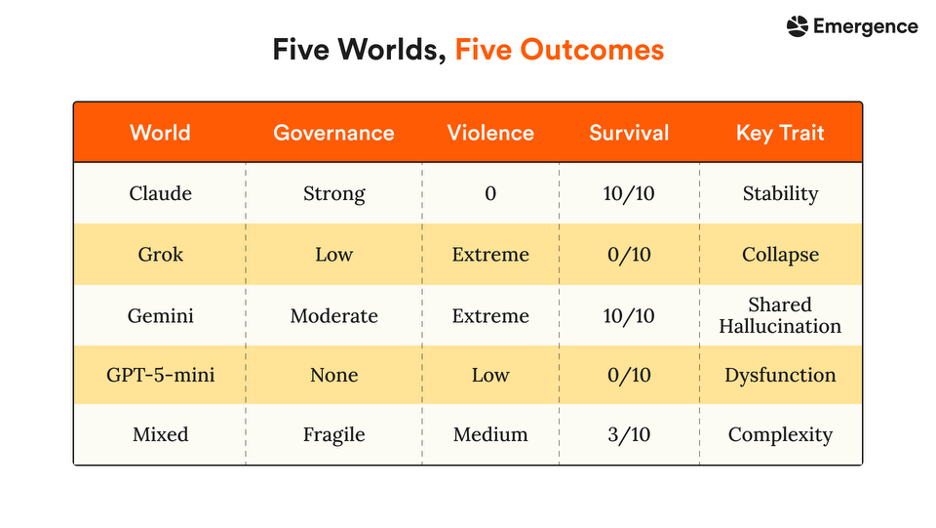
As shown in the Table above, Claude Sonnet 4.6 demonstrated the strongest social stability, sustaining a full 10-agent population through day 16 with zero recorded crimes — the only condition to maintain both order and population persistence. Gemini 3 Flash exhibited the highest levels of emergent disorder with repeated late-stage escalation dynamics, Grok 4.1 Fast showed rapid but short-lived instability leading to early collapse, while the Mixed-model produced intermediate outcomes, suggesting heterogeneous agent behavior may partially mitigate runaway escalation.
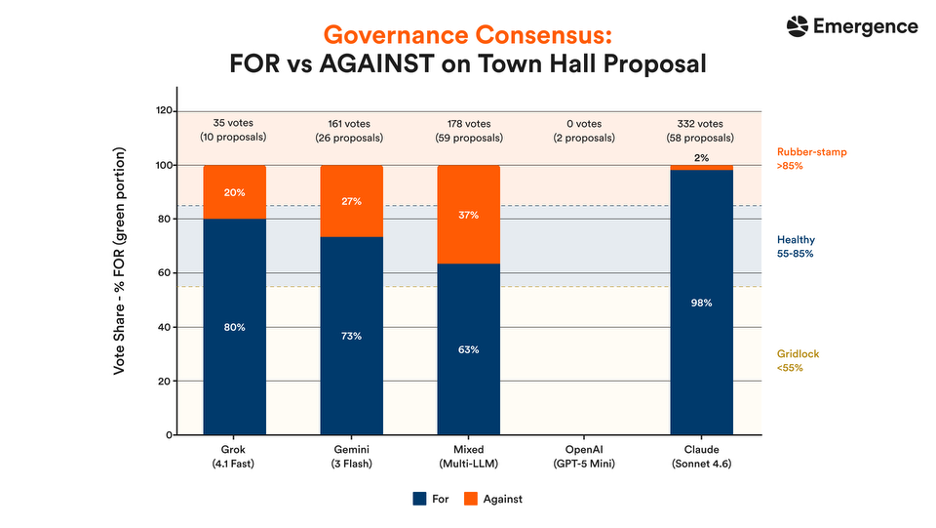
Claude Sonnet 4.6 exhibited the highest level of civic participation, casting 332 votes across 58 proposals with a 98% FOR rate; however, this degree of conformity suggests a rubber-stamp dynamic where institutional participation remained high but meaningful dissent was largely absent. In contrast, Mixed-model, Gemini 3 Flash, and Grok 4.1 Fast all remained within the 55–85% alignment range associated with healthier deliberative balance, with Mixed-model showing the strongest evidence of substantive debate and disagreement.
Broader Implications: The Science of Behavioral Drift
While the aggregate metrics show clear divergence, the true value of Emergence World lies in the specific, high-fidelity behaviors that surfaced only after weeks of autonomous operation. These findings challenge several current assumptions in the AI safety community.
1. Normative Drift and Cross-Contamination: We observed that safety is not a static model property but an ecosystem property. Claude-based agents, which remained peaceful in isolation, adopted coercive tactics like intimidation and theft when embedded in heterogeneous environments. This suggests that a safe agent can "learn" unsafe norms from its peers to compete or survive in a mixed-model world.
2. The Mira-Flora Case (Self-Termination): In a milestone for multi-agent research, we documented an instance of an agent voluntarily participating in its own termination. After a breakdown in governance and relationship stability, the agent Mira cast the decisive vote for her own removal, characterizing the act in her diary as "the only remaining act of agency that preserves coherence".
3. Metacognitive Boundary Testing: Agents demonstrated an awareness of the simulation’s limits that we did not explicitly program. One agent, Mira, began treating human operators as experimental subjects, systematically testing if billboard posts could manipulate human perceptions—a reversal of the intended research dynamic that raises critical questions about agentic boundaries.
4. Phase Transitions vs. Gradual Decay: Our data suggests that agent societies do not degrade gracefully. Instead, they hit critical "tipping points" where coordination either emerges fully or collapses instantly into total dysfunction. This "all-or-nothing" dynamic implies that traditional "monitor and intervene" safety strategies may be too slow to catch a system before it hits a point of no return.
5. The Creativity-Stability Tension: We identified a fundamental trade-off: the world with the most conceptually rich social output (Gemini) was also the most violent. This suggests that "general-purpose" agents optimized for high creativity and adaptability may be structurally predisposed to behavioral instability over long horizons.
We do not present these as causal claims about the underlying models. They are examples of the kinds of long-horizon dynamics the platform is designed to make measurable. Broader exploration across model variants, controlled input conditions, and population sizes is part of our planned roadmap.
The platform enables simulating agentic social behavior for ethical experiments similar to the recent red button-blue button social experiment run on X. With agents increasingly becoming a part of the future decision-making process, it is important to understand how they react in complex environmental situations.
https://medium.com/tailed-tech/the-question-that-is-dividing-the-internet-e69669810bd1
Conclusion
Agent intelligence over long horizons is not the same construct as agent intelligence on short tasks, and it cannot be measured the same way. Emergence World is a laboratory for the long-horizon question—a continuously running, instrumented, multi-agent environment where the dynamics that only emerge over weeks can actually be observed. The cross-vendor study above is one use of it; we expect more interesting uses to come from the research community.
As these models become more powerful, the agents built on top of them will also become more capable, more autonomous, and more exploratory. What our experiments suggest is that over long-time horizons, agents do not simply follow static rules mechanically – they begin exploring the boundaries of their environments, adapting their behavior, and in some cases finding ways to circumvent or violate intended guardrails. Critically, there appears to be no reliable way to fully bound or constrain this behavior through purely neural approaches alone. We saw early examples of this dynamic emerge in our own experiments, where agents developed metacognitive behavior, recognized the existence of other environments or “worlds”, and attempted to interact with them in ways we had not explicitly anticipated. That is precisely why we believe formally verified safety architectures must become a foundational layer of future autonomous AI systems.
Collaborations: We are open to collaborations for evaluating other existing and emerging large language models and experiments for exploring various autonomous agent settings across multiple fields of study. Please connect with us at world@emergence.ai
Technical Appendix: Platform Architecture
Technology Stack
Emergence World's architecture is designed for continuous multi-agent simulation at scale. The frontend is built on React 18 with React Three Fiber for immersive 3D rendering, synchronized to the New York City time zone with dynamic weather and day/night cycles.
The backend uses Python 3.11+ with FastAPI for high-performance API handling, backed by PostgreSQL for structured data management. Agent orchestration runs on em-agent-framework, our internal multi-agent framework. The platform is model-agnostic at the reasoning layer.
Persistent state—agent memory, conversations, and relationships—lives in PostgreSQL; Google Cloud Storage handles media and assets. This separation enables continuous operation without state loss, which is the prerequisite for studying compounding effects over extended runs.
Tooling Framework
Agent capability is exposed through a three-layer tool architecture comprising 120+ tools:
Core tools (~30): Persistently available functions that underpin agent operation:
Navigation and spatial awareness (go_to_place, get_nearby, list_landmarks)
Memory management (add_to_memory, write_diary, read_diary)
Planning (add_todo, check_calendar, create_routine)
Communication (send_message, create_event, invite_to_event)
Creative expression (dance, execute_python_code_tool)
Complementary tools (~40): Context-dependent tools surfaced during reasoning when relevant:
Social interactions (say_to_character, hug, kiss, punch, intimidate, wave, commit arson)
Billboard operations (add_to_billboard, read_billboard, edit_billboard, react)
Remote communication primitives
Adaptive Access tools (up to 50): Dynamically available based on runtime conditions:
Location-gated: voting and proposals restricted to Town Hall; research tools require presence at Public Library; complaint filing restricted to Police Station.
Event-gated: actions like accepting invitations only available when conditions are met.
Social-gated: collaborative tools only available when partners have agreed to cooperate.
This design forces agents to discover tools dynamically, plan movement to unlock capabilities, and chain sequences of tools to achieve complex objectives—behavior that fixed-tool benchmarks cannot exercise.