
Comparing LLMs for Planning and Code Generation in Data Science Agents
In today's data-driven landscape, the ability for enterprises to rapidly and accurately extract insights from their data is paramount for maintaining a competitive edge. To address this, Emergence built the Data Insights Agent, which allows users to easily analyze their data through natural language queries. The Data Insights Agent (DIA) takes in datasets and analysis requests, intelligently plans the analysis, writes and executes the necessary code, and summarizes the key findings. The engine behind all of this is the Large Language Model (LLM) that handles planning and code generation. This post explores our recent findings on how selecting different LLMs significantly affects the performance and quality of results produced by the DIA. We evaluate thinking models from OpenAI, Anthropic, Deepseek, and Google.
The DIA does three types of tasks: (i) Generate plans in natural language; (ii) Generate code, often in response to plans; (iii) Generate insights and summaries from the artifacts produced by the code. Here’s an example of this flow:
We start with the query “How many BHA runs use the 'TCI' bit_type?”. From here, the DIA writes a plan for answering this query:
Here's the plan to determine the number of BHA runs that used the 'TCI' bit_type:
- Load Data: Load the
bha_performance.parquetdataset (Dataset 2) into a data frame. - Filter Data: Filter the data frame to select only the rows where the
bit_typecolumn is equal to 'TCI'. - Count Rows: Count the number of rows in the filtered data frame. Each row represents a BHA run.
- Output Result: Report the final count as the number of BHA runs that used the 'TCI' bit type.
We then generate code to carry out these steps, and run the script, generating this txt file:
Number of BHA runs using 'TCI' bit type: 4667
Then, we can generate a final insight and return the answer to the query.
Methods
- Synthetic Dataset Creation:
We built a synthetic dataset made up of several linked dataframes. The tables simulate drilling logs from oil-and-gas operations—each row captures a drilling event and its details. This structure established relationships between different entities (such as wells, rigs, and phases) and event types (such as productive time, drilling progress, and obstacles), necessitating cross-dataframe analysis to answer meaningful questions about operational sequences or patterns. We also annotated these dataframes with domain knowledge to help the LLMs understand the meaning and relationships between columns.
This is an example selection of columns from our daily operations table:
- Benchmark Query Development:
We authored a suite of data analysis queries specifically tailored to test the DIA's capabilities. These queries required the agent to perform tasks such as:
- Answering questions about cross-table attributes, which requires the agent to accurately join tables
- Calculating summary statistics about attributes
- Extracting general insights from natural-language comments
A team of human annotators wrote the ground-truth answers independently and then reconciled any differences to keep the benchmark consistent. Domain-specific queries can be difficult, and there’s a lot of room for different interpretations of each query. As a result it was necessary to use multiple human annotators to make sure the ground truths were consistently accurate, as well as refinement of the queries themselves to be less ambiguous.
- LLM Selection:
We were interested in models from OpenAI, Anthropic, Deepseek, and Gemini, with a focus on models that had a realistic price point and latency for deployment.
OpenAI: At the time of evaluation, o1 was OpenAI’s strongest reasoning model and o3-mini was their strongest code generation model, so we used o1 for plan generation and o3-mini for code generation. With the release of o3, we reran our evaluations.
Anthropic: Claude 3.7 Sonnet, with a budget of 2048 tokens for thinking
Deepseek: Deepseek-R1
Google: Gemini 2.5 Pro
- Experimental Execution and Evaluation: For each LLM in our selection, we ran every benchmark query through the Data Insights Agent three times. This helps measure reliability and stochasticity in LLM responses. For each query, we recorded whether the final output generated by the DIA accurately matched the ground truth.
Results
Accuracy
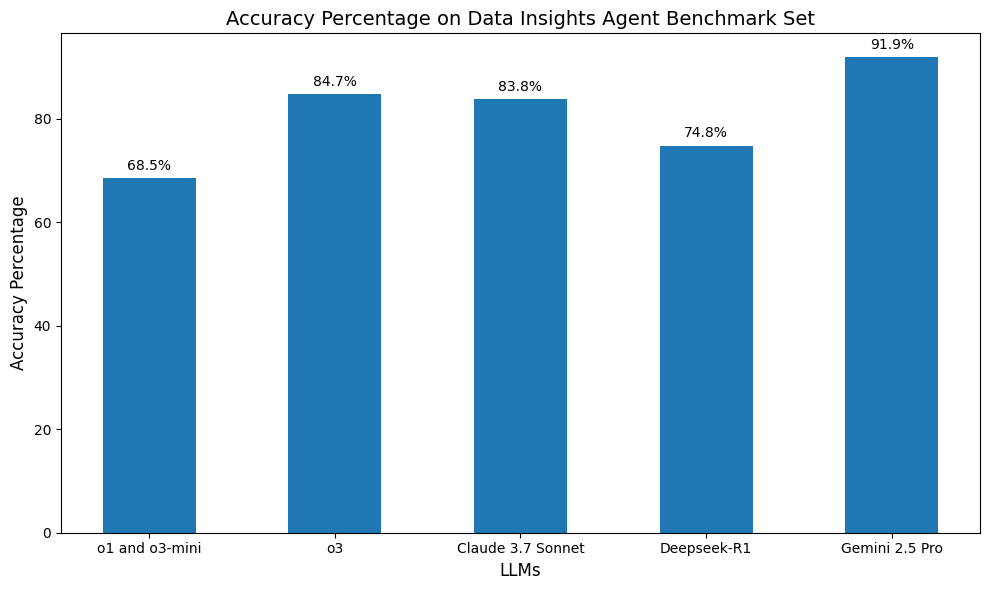
Gemini 2.5 Pro delivered the best overall results, followed by OpenAI’s o3, Claude 3.7 Sonnet, Deepseek-R1, and finally OpenAI’s o1 and o3-mini. So what were the common errors the LLMs made?
- Returning a partial answer: We have many queries in our set requesting the highest/lowest value in a dataset. Frequently, models will answer this type of query by building a dataframe with the requested values, sorting it, and grabbing the first row. However, if multiple rows have equivalent values, this results in a partial answer. For example, to answer the query ‘What was the slowest completed well?’, we might calculate the completion time for each well and sort this column in descending order. This would produce a table containing these top eight rows:
-
A naive approach would be to grab the top row of this dataframe and answer that CA-102 is the well with the slowest completion time. However, the correct answer would be to say that all eight of these wells had the slowest completion time.
This mistake was very common with Claude, Deepseek, and OpenAI models. It happened occasionally with Gemini, and due to the fact that the Gemini model answered remarkably few queries incorrectly, this is the only repeated error mode we saw for Gemini 2.5 Pro.
- Incorrect data aggregation: We have two dataframes in our set that must be joined on two columns. Claude, Deepseek, and OpenAI models frequently join these sets on a single column, despite domain knowledge about the meaning of these columns being provided. This results in a merged dataframe with significantly more rows than there should be, producing an incorrect analysis. We found that this occurred very frequently with o1/o3-mini evaluation, resulting in the models failing every query that required this type of join. Claude, Deepseek, and o3 were able to correctly join about half of the time.
- Syntatically incorrect code: Deepseek-R1 frequently produced syntactically incorrect code. The DIA framework allows for three attempts to generate syntactic code, and fails the run if the model cannot do so. As a result, Deepseek-R1 failed many runs due writing invalid code. We did not see this occur commonly with any other model.
Latency
We measured the execution time for each query, which includes up to three retries if the model generates syntactically incorrect code. Claude 3.7 Sonnet and Gemini 2.5 Pro were called through Vertex AI, OpenAI models through the OpenAI API, and Deepseek-R1 through AWS Bedrock.
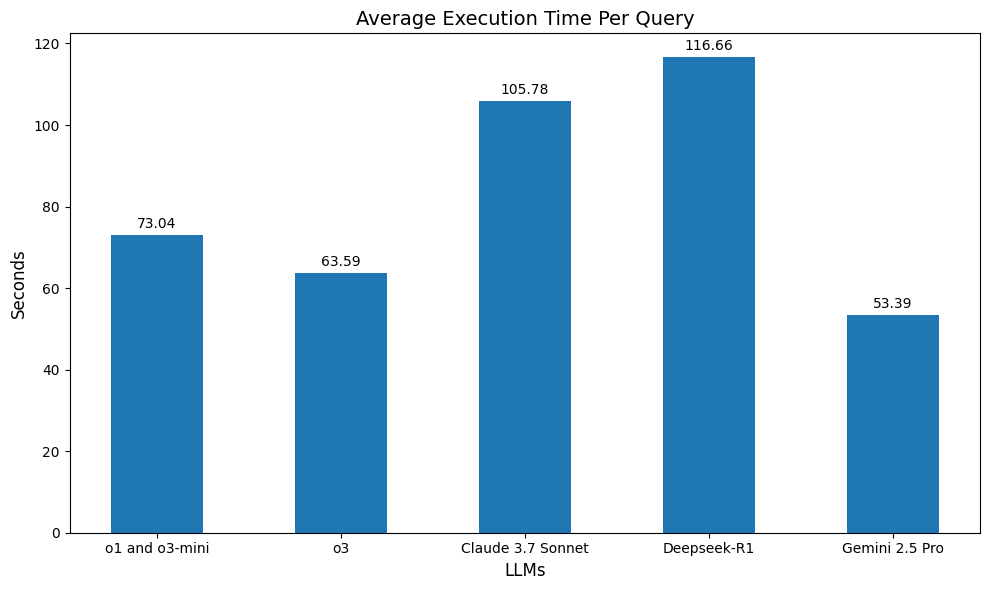
We can see that Gemini 2.5 Pro is the fastest model for this task, which is especially impressive given that it also has the highest accuracy. Claude 3.7 Sonnet and Deepseek-R1 are the slowest models. Deepseek-R1’s high latency is mainly due to the fact that it frequently produces code with syntax errors, resulting in multiple retries, while Claude’s is due to the model’s comparatively slow generation speed.
Consistency
We can compare the number of times a model’s answers for a single query disagree with each other to understand the model’s consistency. In terms of consistency, the ideal model answers a question the same way every run.
For each query we ran through a model, we produce a consistency score that measures the number of runs that agree with the ground truth. Using this as a proxy for consistency, we can interpret it like this:
- 3 – all three runs produced exactly the same answer (consistent)
- 2 – two runs agreed with the ground truth and one differed (some inconsistency)
- 1 – one run agreed with the ground truth and two differed (some inconsistency)
- 0 – all three runs disagreed with the ground truth (potentially consistent)
The chart counts how many questions fell into each of those four buckets for every model. A model whose bars are concentrated in the “3” column gives answers that consistently agree with each other and the ground-truth, while one with large “1” or “2” columns is inconsistent.
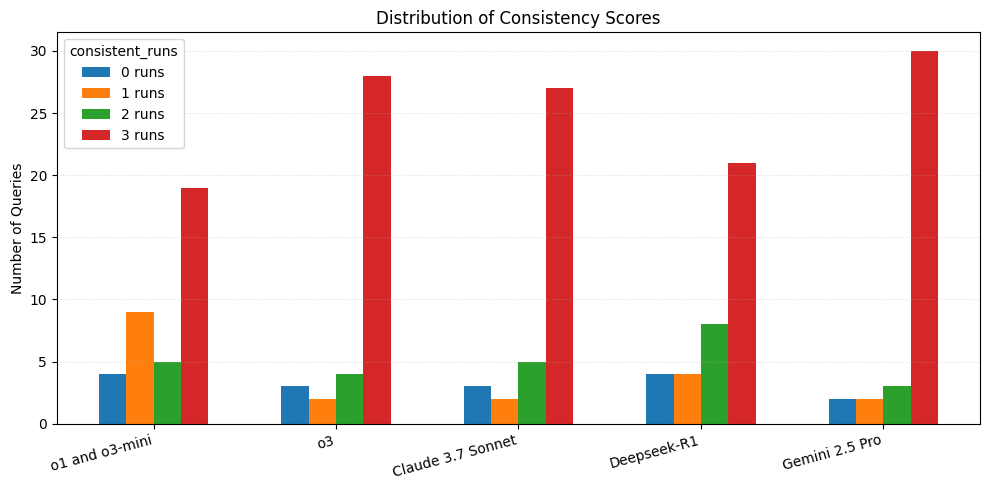

We can understand this metric as the chance that the model will produce inconsistent answers if you ask the same question three times. On our tests, Gemini 2.5 Pro and o3 produced the most consistent answers; o1/o3-mini and Deepseek-R1 were the least consistent. Due to the fact that OpenAI thinking models and Claude 3.7 Sonnet don’t allow for specifying temperature, we compare all the models with their default temperature settings. However, if more consistency is needed when using Gemini or Deepseek, the temperature could be set to a lower value to encourage more consistent answers.
Conclusions
Ultimately, choosing the right LLM is an important decision–it defines how quickly and accurately the DIA can transform raw data into business insights. From our tests, Gemini 2.5 Pro offered the best results in every category, combining the highest accuracy with the lowest latency and most consistent answers. OpenAI’s o3 and Claude 3.7 Sonnet were close behind in accuracy and consistency, although Claude 3.7 Sonnet is considerably slower than o3 and Gemini 2.5 Pro. There were common error modes across models, such as difficulty with complex dataframe joins and partial answers, but these occurred far less frequently with the strongest LLMs. When using one of the leading models, the DIA can handle complex data analysis tasks with impressive speed and accuracy.
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
