
Building Narrow Self Improving Agents
A number of enterprise workflows involving language- and tool-control tasks can be augmented with LLM- and LVM-powered agents. Given the diversity of input scenarios in enterprise tasks involving language and tool control, these agents need to improve constantly as they encounter new configurations and inputs in their environment. Broadly, self improvement can take two forms:
1) Narrow self-improvement: This category involves agents which improve their performance within the context of a fixed operating environment or goal. The agents are not expected to learn or exhibit new capabilities that are outside the scope of their respective goals.
2) Broad self-improvement: This category encompasses broader and more sophisticated modalities, including agents that can create tools, modify their own architecture, and even create new agents. The latter has sometimes been termed “recursive self-improvement,” and it has been conjectured/feared to potentially enable “intelligence explosion” and/or “AI-takeoff.”
Many enterprise scenarios where agents are deployed could benefit from narrow self-improvement. For example, a text summarization agent, built on top of an LLM custom-tuned for the task, would continue to improve it capabilities to summarize as new examples were provided to it. Once narrow self-improvement agents are given their goals, they monitor their own performance against those goals and autonomously kick off a fine-tuning loop, retraining their capabilities (including their underlying LLMs or LVMs) using a new dataset.
A key aspect of narrow self-improvement is that the goal-oriented agent learns by new examples that are either generated by humans or other AI agents (termed “teacher agents”) that are somehow deemed superior at achieving the given goal. Normally, teacher AI agents are not only more capable at achieving the goals but are also more expensive or resource-intensive for the considered environments; hence why they cannot simply be used as replacements for their student goal-oriented agents (i.e. they are good as teachers, but not as executors).
For further understanding and tractability of the narrow self-improvement problem, we unpack it into the following framework:
1) Why does an agent need to self-improve? In a realistic deployment setting, self-improvement may be triggered for a number of reasons. On the one hand, the target of self-improvement could be to just satisfy the defined goal up to some acceptable threshold as provided by the administrator of the agent. On the other extreme, it could be to maximize its operational efficiency, incentives, or outputted value (defined by a value function).
2) What should trigger an agent to self-improve? The agent by itself may not know why its performance is not where it should be, and hence it may not know what exactly it should improve. On the one hand, the agent could self-analyze (introspect) to understand which part of itself it could improve to get the maximum return (exactly how we could achieve such introspection is intriguing and a subject of future thought). On the other hand, and more pragmatically, the improvement could be triggered based on explicit feedback from a “feedback agent” (which by itself could operate on a combination of human input and that of a more capable LLM-agent) or a “planning and optimization agent.”
3) When does an agent trigger self-improvement? Exactly when an agent begins the process of self-improvement can be based on various kinds of policies. It could be time-based, which means the agent goes into self-improvement at regular intervals, usually in order to keep up with changing data distribution. This is the simplest of the policies and is akin to regular servicing of any system to keep it running at top performance. Another policy could be performance-based, where the agent keeps track of its performance history over a set of its last N tasks. If the agent notices a declining performance trend, it could decide to go into a self-improvement loop. For example, if the performance over the last N summarizations has a declining trend based on the feedback by the task manager or the user (thumbs up and down, say), the agent may trigger a self-improvement loop. Yet another policy could be based on return on investment. Self-improvement is always a cost to the system in terms of getting new samples from a teacher agent or human, and it also diminishes the utility of the agent in the system for a period of time. Therefore, a decision on self-improvement could be based on what it would cost an agent to self-improve vs how much of an increase in utility might be seen. If it satisfies a particular return of utility on the cost of re-training, the agent may trigger self-improvement.
4) How does an agent trigger self-improvement? This question deals with an agent’s ability to decide what strategy to employ to improve itself. The requirement motivates a planning and optimization agent that provides a plan of action for the agent to improve itself given the goal and metrics of success. For example, if the plan requires the agent to get some quality training samples or demonstrations from a teacher model or a human teacher, the framework sets up the various endpoints necessary to get those samples. Once the plan is satisfied, the evaluation agent checks against the metrics specified to see whether they were met. If the plan is not satisfied, the agent is sent back to the planning and optimization agent to create a new plan. Similarly, a self-improvement plan could involve self-play of the agent to improve its capability. There too, the agent would employ well-defined metrics on when it can consider its self-improvement done. Further, a mechanism is needed to decide whether the agent goes out of operation during self-improvement, or rather creates a clone of itself that continues its operation until the original agent comes back from self-improvement.
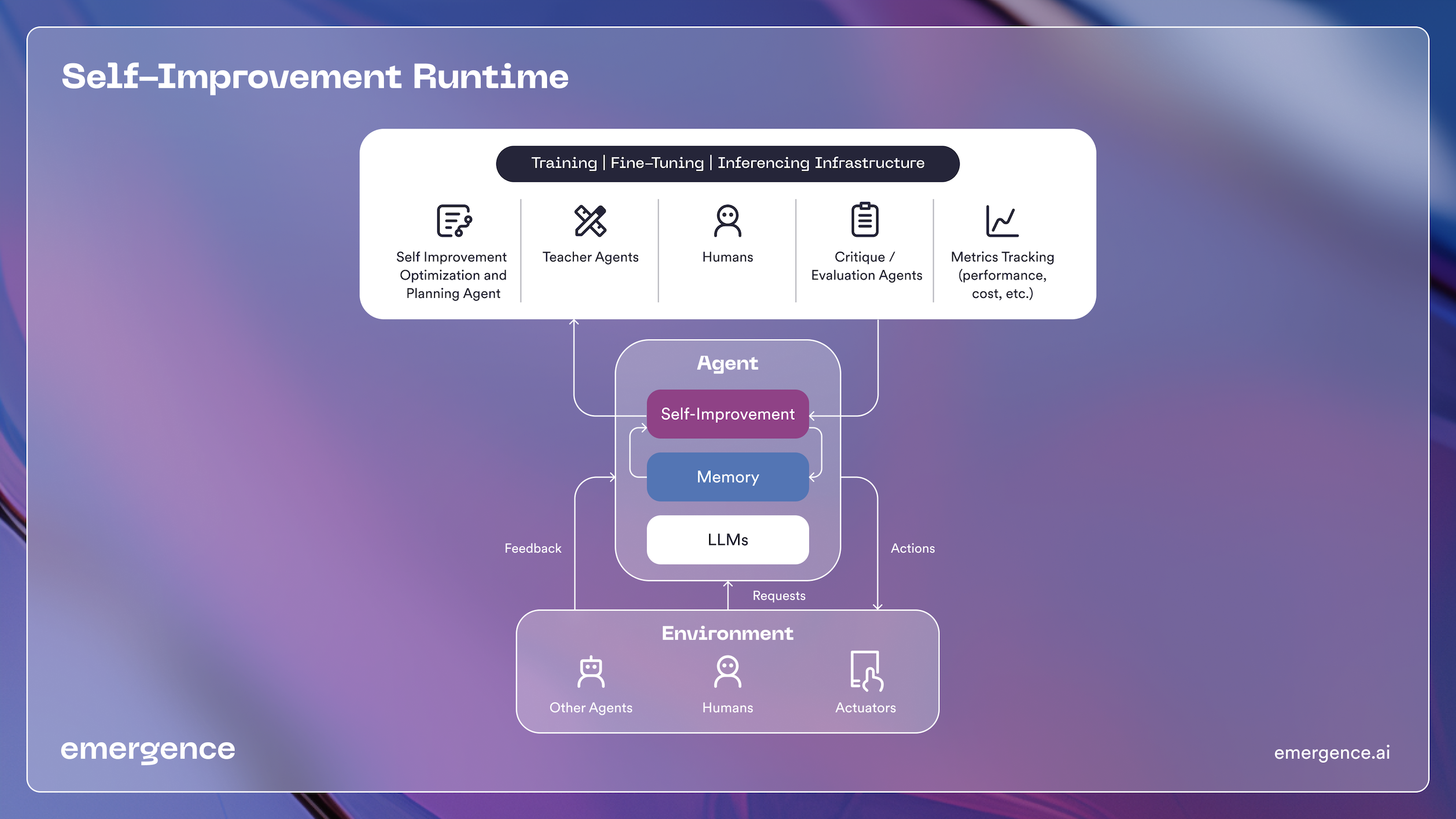
Based on the above framework, Emergence is building a runtime (see figure below) that provides a seamless orchestration of the various steps of narrow self-improvement. The agent itself could be part of a group of multiple agents or part of a human augmentation, meaning its feedback loop arises from two areas. One area is the critiquing or feedback agent in the self-improvement runtime and the other could be agents or humans from the environment in which it is operating. The agent incorporates both of these feedbacks when it undergoes self-training. The latter triggers self-improvement and the former maintains the integrity of that self-improvement. The details of the modules of the runtime are explained below :
- Monitoring: The agent (referred to as Agent-A) gathers feedback about the performance of this existing execution flow, including the LLMs and LVMs used.
- Planning and Optimization: Once Agent-A realizes that it needs to improve its performance, a planning agent helps it diagnose and plan the best course of improvement of its performance. It is possible that the performance of an LLM in an agent can be improved using SFT samples generated from a teacher-LLM, or it could need human demonstration samples to improve its performance.
- Data Generation: Agent-A uses the plan and the diagnosis prepared by the planning agent to generate samples using one or more teacher-LLMs or humans to create training/fine-tuning datasets that improve its LLM.
- Training: Agent-A deploys itself automatically on a training infrastructure, where the infrastructure uses the agent’s configuration manifest to deploy it in the right infrastructure for training. The training scripts automatically run the training activity and create a new version of the LLM inside the agent.
- Benchmarking and Evaluation: The evaluation agents help in benchmarking the new model using a combination of validation datasets created using teacher-LLMs or humans-in-the-loop
- Deployment: Once the training metrics are validated, Agent-A deploys itself on the production infrastructure where it is monitored in an A/B testing scenario, and it replaces its previous clone once a performance metric is met.
Self-improvement is one of the core aspects of an AI agent. By continuously learning, adapting, and optimizing their actions, these agents can help us make better decisions, streamline processes, and ultimately bring huge productivity gains in human-agent workflows. However, it is important to approach the development and deployment of self-improving agents carefully to ensure that the self-improvement process always meets the agent’s goals and does not cause unnecessary inefficiencies. Further, any self-improvement needs to be enabled with caution, ensuring that ethical considerations, transparency, and accountability are prioritized.
References
[1] https://www.lesswrong.com/tag/recursive-self-improvement
[3] Legg, S., & Hutter, M. (2007). Universal Intelligence: A Definition of Machine Intelligence. Minds and Machines, 17, 391-444.
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
