
The Validation Imperative in Agentic Science
The Landscape of AI Scientists
AI agents have transformed multiple domains over the past few years. In software development, systems like GitHub Copilot handle complex programming tasks with increasing autonomy. Customer service chatbots resolve queries without human intervention. Data analytics platforms automatically generate insights. These successes share common features: clear objective functions, instant validation through automated checks, and low costs of failure. The question now facing the field is whether similar autonomy can extend to scientific research.
Hundreds of companies across multiple scientific domains are building AI scientist systems. These range from tools that autonomously search literature and analyze data, to platforms that generate hypotheses through computational exploration, to ambitious systems attempting fully autonomous discovery with robotic experimentation. The technology is impressive: systems can process thousands of research papers overnight, execute tens of thousands of lines of code, run thousands of simulations, and generate detailed scientific reports.
Yet despite billions in investment and remarkable computational capabilities, a persistent gap remains between computational prediction and scientific validation. This gap reveals something fundamental about the nature of scientific knowledge and determines where computational agents can deliver genuine value versus where they risk generating impressive but ultimately ungrounded claims.
Prediction vs Knowledge: The Validation Question
At the heart of agentic science lies a critical question: Is computational prediction, no matter how sophisticated, scientific knowledge by itself? Or does it remain a hypothesis until validated against physical reality?
The distinction matters because it determines the entire architecture of useful AI scientist systems. If computational predictions constitute knowledge, then autonomous systems can generate scientific discoveries by operating purely in the digital realm. If computational predictions are hypotheses requiring physical validation to become knowledge, then the architecture must explicitly connect computational exhaustiveness to experimental validation, with human judgment navigating the bottleneck between inexpensive predictions and costly experiments.
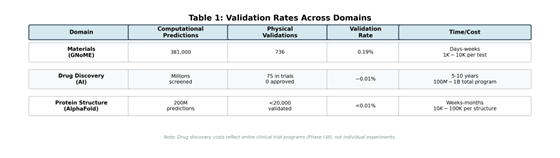
The evidence from the field strongly supports the latter view. In materials science, Google DeepMind’s GNoME system predicted approximately 381,000 stable materials with improved computational accuracy over previous algorithms (Merchant et al., 2023). Yet external researchers have validated only 736 experimentally—a 0.19% validation rate. The scientific community treats these as predictions awaiting validation, not confirmed discoveries.
Drug discovery tells a similar story. Over 75 AI-designed molecules have entered clinical trials, representing years of computational work and billions in investment. Zero have achieved regulatory approval as of 2024-2025. Computational predictions consistently fail to translate to clinical efficacy when tested in humans.
Systems operating primarily in the computational realm demonstrate both the power and limitations of this approach. Kosmos, developed by Edison Scientific, exemplifies sophisticated computational research, reading thousands of papers and executing tens of thousands of lines of code per run to generate detailed reports across metabolomics, materials science, and neuroscience (Mitchener et al., 2024). However, the system’s authors explicitly acknowledge the validation gap as a limitation: all seven reported discoveries involved computational validation only with zero new wet-lab experimental validation conducted during runs.
Across domains, computational systems optimize for internal coherence (stability under learned representations, consistency with historical data) while physical validation tests external correspondence (how predictions behave under uncontrolled real-world conditions). Scaling computation improves internal coherence faster than external correspondence. As a result, confidence grows faster than reality.
Empirical benchmarking confirms this gap: state-of-the-art LLMs show persistent performance degradation on discovery-grounded tasks tied to real research scenarios compared to decontextualized question-answering (Song et al., 2025). The pattern is consistent: computational prediction requires physical validation to become scientific knowledge. Validation is not merely a crutch for imperfect models; it is the mechanism by which science interrogates the unknown.
The Validation Bottleneck: An Amdahl’s Law Constraint
Scientific progress follows an iterative cycle. The diagram below illustrates how validation acts as a fundamental bottleneck constraining the entire discovery loop:
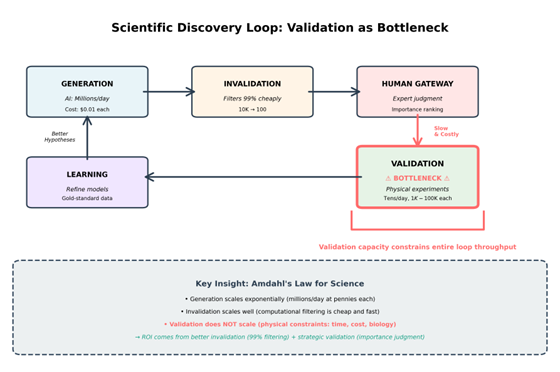
Validation (physical experiments) constrains the entire loop’s throughput, analogous to Amdahl’s Law in parallel computing where a serial bottleneck limits overall speedup regardless of parallelization in other stages. The gap exists because of an irreducible asymmetry: computation scales exponentially while physical experimentation remains constrained by the fundamental costs of manipulating matter and measuring biological systems.
Current state: - Generation: AI produces millions of predictions per day at pennies each - Validation: Tens to hundreds of experiments per day, $1K to $100K each - Ratio: 10,000:1 to 1,000,000:1 (computational speed / experimental speed)
Robot labs improve throughput substantially (Szymanski et al., 2023), but this barely addresses a gap spanning multiple orders of magnitude. Clinical trials cannot be accelerated beyond biological constraints; patients respond to therapies at human rates regardless of computational power applied.
This bottleneck forces a critical decision: which computational predictions warrant expensive physical testing? With hundreds of thousands of material predictions and budget for hundreds of validations, the choice requires importance judgment. No training signal exists for “importance”; it emerges from scientific community consensus over time. Materials scientists chose which GNoME predictions to validate first based on battery applications, superconductor potential, and industrial relevance. Human judgment provided the strategic allocation that computational optimization alone cannot deliver.
Given these fundamental constraints, how have successful systems navigated the validation bottleneck in practice?
Evidence from Working Platforms
The architecture that works combines computational exhaustiveness with human validation gates. Multiple platforms demonstrate this approach with quantified results. MIT’s CRESt platform, published in Nature in 2025, explored 900 chemistries through 3,500 experiments, discovering a fuel cell catalyst with 9.3-fold power density improvement per dollar compared to pure palladium. Academic work on Bayesian optimization demonstrates consistent efficiency gains, with active learning approaches requiring substantially fewer experiments than random or grid search methods to identify optimal solutions (Huang et al., 2021; Shields et al., 2021).
Every successful implementation incorporates human-in-the-loop at validation gates. Scientists review computational proposals, apply importance judgment, validate feasibility, and decide which designs warrant physical testing. The pattern is universal: computational exhaustiveness (agents test hundreds to thousands of possibilities), human validation gates (choosing which matter for research goals), physical experiments (confirming expert-approved designs), and results feeding back to improve models.
AlphaFold’s success illustrates how decades of physical validation create the foundation for computational breakthroughs. The system achieved its 2024 Nobel Prize because 50 years of crystallography and electron microscopy generated the Protein Data Bank—experimentally validated structures from physical experiments (Jumper et al., 2021). AlphaFold is now a tool within broader research pipelines requiring continued physical validation, not an autonomous endpoint. Researchers use predicted structures for drug design, but these computational predictions still require validation through synthesis, biochemical assays, cellular testing, and clinical trials.
The Invalidation Opportunity: Scaling Through Rapid Filtering
While physical validation remains the constraint, computational invalidation—rapidly discarding wrong hypotheses—can scale orders of magnitude more effectively. This represents the primary opportunity for productivity gains.
Invalidation vs Validation: Different Economics
Validation (confirming a hypothesis is correct): - Requires physical experiments - Expensive ($1K - $100K per test) - Slow (days to years) - Constrained by material/biological limits - Does not scale
Invalidation (confirming a hypothesis is wrong): - Can use computational filters - Cheap ($0.01 - $10 per test) - Fast (seconds to hours) - Limited only by compute capacity - Scales exponentially
Evidence shows LLMs can excel at hypothesis space exploration even when lacking deep domain knowledge. In transition metal complex optimization, models achieved near-optimal solutions despite poor performance on predicting fundamental properties, demonstrating “serendipitous exploration” that enables rapid filtering without perfect mechanistic understanding (Song et al., 2025).
The Scaling Equation
When validation capacity is the bottleneck, discovery rate depends on the success rate of validated candidates:

Concrete example:
Consider generating 1M hypotheses daily: 999,000 false + 1,000 true. With 90% invalidation efficiency, we filter out 899,100 false hypotheses, leaving 99,900 false + 950 true (lost 50 to 5% false positive rate). This 100,850-candidate pool has 0.94% success rate. With 100 validations/day capacity, you produce roughly 1 discovery per day. Improve invalidation to 99% efficiency: we now filter out 989,010 false hypotheses, leaving 9,990 false + 950 true. This 10,940-candidate pool has 8.7% success rate, yielding approximately 9 discoveries daily from the same 100 validations. Better invalidation improves discovery rate 9×, while 10× more generation without better invalidation merely creates a longer queue.
Note that as invalidation filters improve through learning from validation results, the baseline quality of generated hypotheses should also improve (higher proportion of true hypotheses in the initial set), creating a compounding effect beyond the direct invalidation gains shown here. This feedback loop - better invalidation teaches better generation - is why the integrated architecture delivers multiplicative rather than additive improvements.
The Architecture for Validation-Gated HITL
The validated architecture is Validation-Gated HITL: computational agents explore exhaustively, computational filters eliminate the obviously wrong, human experts gate transitions to physical validation based on importance and feasibility, experiments test strategically, and results generate gold-standard data improving future predictions.
The Integrated Architecture
Layer 1: Computational Exhaustiveness (AI Autonomous) - Search literature comprehensively, analyze datasets systematically, simulate designs exhaustively - Generate hypotheses at scale through combinatorial exploration - Leverage: Computational scale that humans cannot match
Layer 2: Computational Invalidation (AI with Physics Constraints) - Apply physics-based filters (thermodynamic stability, synthetic accessibility, toxicity prediction) - Screen for known failure modes, eliminate constraint violations - Rank by proxy objectives (predicted binding affinity, formation energy) - Goal: Reduce candidate set by 99% using cheap computational tests (from millions to thousands)
Layer 3: Expert Validation Gateway (Human Judgment) - Apply importance judgment (which survivors matter scientifically/commercially?) - Assess feasibility (which can be synthesized/tested with available resources?) - Evaluate strategic fit (which align with program goals?) and risk (acceptable failure modes?) - Determine sequencing (what to test now versus later to maximize learning?) - Decision: Which 10-100 candidates warrant expensive physical validation?
Layer 4: Physical Validation & Feedback (Experiments) - Test scientist-approved designs in physical systems, measure actual outcomes - Generate gold-standard data revealing model failures and approximation limits - Feed results back to refine both invalidation filters and generation quality - Connect: Computational prediction to biological/physical reality
Net effect: Million predictions → 10,000 computational survivors → 100 expert-ranked finalists → 10 physically validated discoveries
This architecture maximizes ROI by leveraging computational scale for cheap invalidation, applying human judgment where strategic allocation is critical, reserving expensive validation for highest-value candidates, and closing the feedback loop from validation results to improve future predictions.
Human judgment is architecturally necessary because scientific experiments involve multi-objective optimization without single best solutions. Chemistry reaction optimization balances yield, purity, cost, and reaction time—objectives that fundamentally conflict. Computational agents can calculate Pareto frontiers showing trade-offs (Shields et al., 2021), but scientists must choose based on strategic context that varies with research stage, budget constraints, and program timelines.
Benchmarking studies confirm this limitation: when given tasks with limited validation attempts, AI systems demonstrate substantially lower success rates than human experts in strategic resource allocation. Humans understand meta-problems (how to allocate scarce resources for maximum learning); AI systems lack the meta-reasoning necessary for efficient allocation when validation is constrained.
Conclusion: The Validation Imperative
After examining this landscape, three conclusions emerge:
1. Science requires connection to physical reality. Predictions are hypotheses that must be tested. Computational validation differs fundamentally from physical validation—models approximate, reality is ground truth. Validation failures teach us, refining models and discovering new physics.
2. The bottleneck is validation capacity and prioritization. With 381,000 predictions and budget for 736 validations (GNoME example), success requires strategic allocation based on what matters scientifically and economically. This is human judgment, not computational optimization.
3. Maximum ROI comes from optimizing the constraint. Not from generating more predictions (already at millions per day), but from better invalidation (filtering wrong hypotheses cheaply at 99% efficiency) combined with strategic validation (testing right hypotheses). The scaling equation makes this explicit: improving invalidation efficiency from 90% to 99% yields 9× more discoveries from the same validation capacity.
Organizations building systems with this architecture—computational exhaustiveness + rapid invalidation + human validation gates + physical experiments + feedback loops—will deliver genuine productivity improvements. Those pursuing autonomous computational prediction without validation pathways will accumulate hypotheses without the physical confirmation necessary to generate scientific knowledge.
Computation is necessary for modern science. But it’s not sufficient. The validation bottleneck is the constraint—and human judgment, combined with rapid computational invalidation, is how we navigate it efficiently.

References
Song, Z., Lu, J., Du, Y. et al. (2025). Evaluating Large Language Models in Scientific Discovery. arXiv preprint arXiv:2512.15567.
Merchant, A., Batzner, S., Schoenholz, S.S. et al. (2023). Scaling deep learning for materials discovery. Nature 624, 80–85.
Jumper, J., Evans, R., Pritzel, A. et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589.
Szymanski, N.J., Rendy, B., Fei, Y. et al. (2023). An autonomous laboratory for the accelerated synthesis of novel materials. Nature 624, 86–91.
Mitchener, L., Chang, B., Yiu, A. et al. (2024). Kosmos: An AI Scientist for Autonomous Discovery. arXiv preprint arXiv:2511.02824.
Huang, B., Symanski, N., Bartel, C. et al. (2021). Benchmarking the performance of Bayesian optimization across multiple experimental materials science domains. npj Computational Materials 7, 188.
Shields, B.J., Stevens, J., Li, J. et al. (2021). Bayesian reaction optimization as a tool for chemical synthesis. Nature 590, 89–96.
More From the Journal

Agentic AI for Enterprise Needs Much More than LLMs

Agentic AI Automation of Enterprise: Verification before Generation
